

儘管世界 人工智能 (AI) 雖然它可能經常看起來像一個動蕩的領域,但在幕後卻有令人驚訝的大量分析、基準測試和測試——不僅是公司本身,還有為確定自己的排名而創建的團體。

這些小組測試了聊天機器人的方方面面,從聊天機器人的能力到完成數學測試,
創建圖像,或提供合乎邏輯的解釋,甚至提供醫療建議,或只是展示她的情緒智商有多高。
在這些不同的測試中,模型在不同領域展現了各自的優勢和劣勢。例如, GPT-5 他擅長科學推理,但在適應新概念的能力方面落後於雙子座和克勞德等人。
這些測試中的每一個都揭示了關於AI模型的新訊息,它們對於提醒我們在不同場景下哪些工具是最佳選擇至關重要。但通常有一個指標被忽略:哪些AI模型能夠提供最佳的使用者體驗?
人類分類系統
一家名為 Prolific 的英國科技公司創立了 名為 Humaine 的 AI 排行榜Prolific 並沒有測試 AI 完成任務的能力,而是使用這些模型測試了不同的使用者體驗。
透過評估 21,352 人使用這些工具的體驗,他們不僅能夠找出整體贏家,還能按年齡、地點(測試在英國和美國進行)和政治信念細分結果。
其中包括以下個人清單:
- 英國:年齡組
- 英國:種族
- 英國:政治觀點
- 美國:年齡組
- 美國:種族
- 美國:政治觀點
團隊讓每位參與者與兩個不同的人工智慧模型進行比較,並要求他們提供回饋,說明哪個模型在每次互動中表現得更好。
這不僅產生了整體優勝者和表現排行榜,還對基本任務表現和推理進行了單獨排名,並產生了溝通、適應力、信任和道德方面的優勝者。
研究結果顯示什麼?

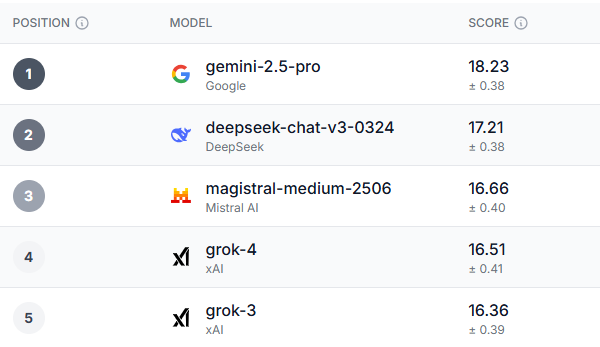
經過全面評測,Gemini 2.5-Pro 不僅在整體表現類別中,而且在大多數子類別中都表現出色,堪稱當之無愧的贏家。 Gemini 2.5-Pro 幾乎在所有測試基準中都表現出色。
英國 18-34 歲的年輕人、民主黨選民以及美國 55 歲以上的人都同意 雙子座2.5專業版 總體而言,這是最好的模型。唯一一個所有人群都排名高於 Gemini 的領域是信任、道德和安全,而 Grok-3 的排名則略顯諷刺——考慮到 AI 模型最近面臨的一些安全和道德問題。
有趣的是,Gemini 之後出現的三個模型分別是 Deepseek、Magistral Le Chat 和 格羅克雖然Deepseek在今年稍早人氣飆升,但最近卻逐漸淡出了人們的視線。而Le Chat雖然人氣稍遜,卻擁有一群忠實的粉絲。
那麼,舉世聞名的 ChatGPT 究竟處於什麼位置呢?它排在榜單的末尾,與評分最高的 GPT-4.1 模型一起位列第八。更糟的是 克勞德,其四屆賽事在總排名中分別位列第十一和第十二名。
那麼,這一切意味著什麼?
這是否意味著 Gemini 是世界上最好的 AI 聊天機器人?這是否意味著你應該拋棄 ChatGPT…?嗯,並非完全如此。
這些結果並不一定反映這些模型的表現。在大多數其他指標上進行測試時,我們通常看到的排名靠前的選項是 ChatGPT、Gemini、Claude 和 Grok。
然而,這是對這些測試的重要補充。它們幫助我們從人類經驗的角度更好地理解人工智慧。例如,Le Chat 在標準基準測試中得分並不高,但在體驗和可信度方面,它經常被認為是一個優秀的選擇。
雖然 Anthropic 和 OpenAI 在本輪測試中的表現未能達到這一水平,但 Gemini 和 Grok 的表現仍然強勁。這兩家公司通常都會在基準測試中取得高分,這次他們也繼續保持這樣的表現。
評論被關閉。