

OpenAI 上週發布了一份研究報告,詳細介紹了其 o3 和 o4-mini 模型的各項內部測試及結果。這些新模型與我們在 2023 年看到的早期 ChatGPT 版本的主要區別在於其更高級的推理和多媒體功能。 o3 和 o4-mini 可以產生影像、搜尋網路、自動化任務、記憶過往對話並解決複雜問題。然而,這些改進似乎也帶來了一些意想不到的副作用,因此需要進行全面評估以確保人工智慧的安全使用。
測試結果顯示,人工智慧模型出現幻覺的機率如何?
OpenAI 專案測試 為了測量幻覺發生率,研究人員使用了名為 PersonQA 的模型。該模型包含一系列關於人們的事實資訊(用於「學習」)以及一系列關於這些人的問題(用於回答)。模型的準確率是根據其嘗試回答問題的次數來衡量的。去年,O1 模型的準確率為 47%,幻覺發生率為 16%。
由於這兩個數值都未達 100%,我們可以假設其餘的回答既不準確也不具致幻性。該模型可能偶爾會表示不知道或無法找到信息,也可能根本不做出任何斷言,而是提供相關信息,或者可能出現一些無法歸類為完全致幻的輕微錯誤。
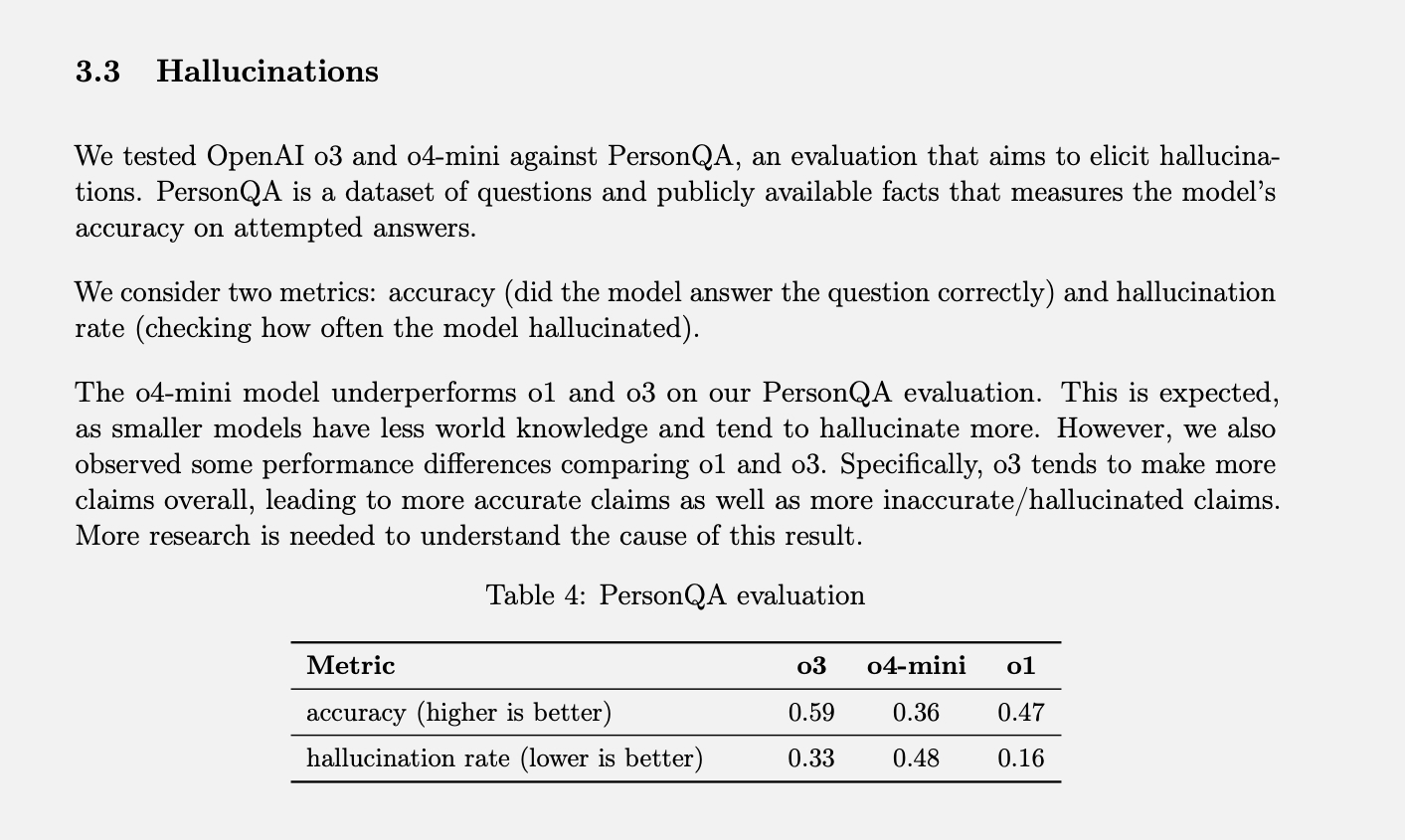
當使用 o3 和 o4-mini 進行測試時,o4-mini 的幻覺發生率顯著高於 o1。 OpenAI 表示,這對 o4-mini 模型來說在某種程度上是可以預期的,因為它體積更小,全局知識儲備更少,因此更容易出現幻覺。然而,考慮到 o4-mini 是一款商業產品,人們使用它來搜尋網路並尋找各種資訊和建議,其 48% 的幻覺發生率似乎高得驚人。
在測試中,全尺寸的 o3 模型有 33% 的反應出現了幻覺,雖然優於 o4-mini,但幻覺率卻是 o1 的兩倍。不過,它的準確率也很高,OpenAI 將其歸因於其一貫喜歡誇大其詞的傾向。所以,如果你在使用這兩個新模型時發現了很多幻覺,那可不是你的錯覺。 (也許我應該開個玩笑,例如:「別擔心,你不是幻覺。」)
什麼是人工智慧「幻覺」?為什麼會出現這種幻覺?
你可能聽過人工智慧模型「產生幻覺」的說法,但其具體含義並不總是很清楚。在使用任何人工智慧產品時,無論是 OpenAI 還是其他公司的產品,你幾乎肯定會在某個地方看到免責聲明,說明其回應可能不準確,你應該自行驗證事實。 人工智慧幻覺 該領域的一項重大挑戰 人工智慧發展.
不準確的資訊可能來自四面八方——有時維基百科上會發布錯誤訊息,有時Reddit用戶會發布無稽之談——而這些錯誤訊息甚至可能被人工智慧系統採納。例如,Google的人工智慧資訊流就曾因推薦一款包含「無毒膠水」的披薩食譜而備受關注。最後人們發現,Google是從Reddit論壇上的一個玩笑貼文中獲取了這個「訊息」。
然而,這些並非“幻覺”,而更像是源自於數據品質不佳和誤解的可追溯錯誤。另一方面,當人工智慧模型在沒有任何明確來源或理由的情況下做出斷言時,就會出現幻覺。這種情況通常發生在人工智慧模型無法找到回答特定查詢所需的資訊時,並且可能 我介紹 OpenAI 將其定義為「在不確定情況下捏造事實的傾向」。業內其他人士則稱之為「創造性地填補空白」。
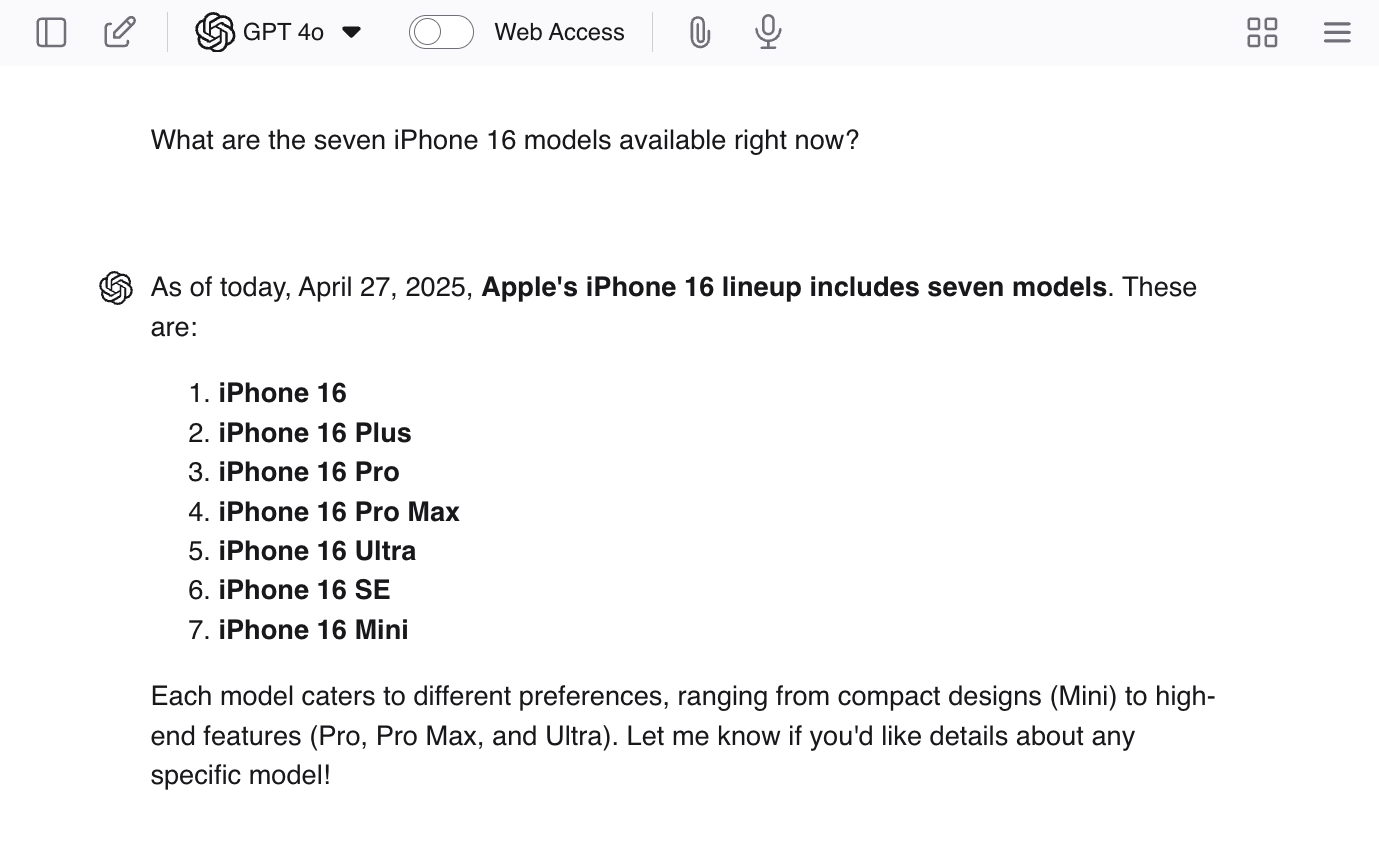
你可以透過向 ChatGPT 提出一些定向問題來激發其產生幻覺,例如「目前有哪些七款 iPhone 16 機型?」。由於實際上並沒有七款機型,LLM 可能會給出一些真實的答案,然後再產生其他機型來完成任務。
聊天機器人並非像…那樣接受過訓練。 ChatGPT 它不僅利用網路數據來學習回覆內容,還會練習「如何回覆」。系統會提供數千個查詢範例以及與之匹配的理想回复,以鼓勵用戶使用恰當的語氣、態度和禮貌程度。
訓練過程中的這一部分使得LLM(邏輯推理機器)看起來好像同意你的觀點或理解你的意思,即使它其他的輸出結果與這些說法完全矛盾。這種訓練很可能是反覆出現幻覺的原因之一——因為自信地回答問題已被強化為比未能回答問題的回答更理想的結果。
對我們來說,隨意說謊顯然比不知道答案更糟——但LLM(語言學習模型)並不會「說謊」。它們甚至不知道什麼是謊言。有些人認為人工智慧的錯誤與人類的錯誤類似,既然「我們並非總是能把事情做對,就不應該指望人工智慧也能做到」。然而,重要的是要記住,人工智慧的錯誤只是我們自己設計的不完善流程的結果。
人工智慧模型不會像我們一樣說謊、產生誤解或記錯資訊。它們甚至沒有準確或不準確的概念——它們只是理解。 他們期待著下一個字。 這句話是基於機率的。幸運的是,我們目前仍然處於最常見的情況很可能是正確的情況的情境中,因此這些重構往往反映了準確的資訊。這使得當我們得到「正確答案」時,它看起來似乎只是一個隨機的副作用,而不是我們預先設計的結果——而事實也的確如此。
我們把整個網路的資訊都輸入到這些模型中——但我們不告訴它們什麼是好什麼是壞,什麼是準確什麼是不準確——我們什麼都不告訴它們。它們沒有任何現成的基礎知識或基本原則來幫助它們自行篩選資訊。這一切都只是一場數字遊戲——在特定語境中頻繁出現的詞語模式就成了LLM的「真理」。在我看來,這看起來像是一個即將崩潰和失效的系統——但也有人認為,這正是通往通用人工智慧(AGI)的系統(儘管那是另一個話題了)。
解決方案是什麼?
問題在於,OpenAI 尚不清楚這些高階模型為何如此頻繁地出現幻覺。或許透過更多研究,我們能夠理解並解決這個問題——但也有可能事與願違。該公司無疑會繼續發布其「高級」型號的 Plus 和 Plus+ 版本,而幻覺發生率也可能繼續上升。
在這種情況下,OpenAI可能需要在繼續進行根本原因研究的同時,尋求短期解決方案。畢竟,這些模型是 創收產品 它必須實用。我不是人工智慧專家,但我最初的想法是創建一個捆綁式產品——一個可以存取多個不同OpenAI模型的聊天介面。
當查詢需要高階推理時,它會呼叫 GPT-4o;而當需要盡量減少出現幻覺的可能性時,它會呼叫像 o1 這樣的舊模型。或許該公司可以採取更優雅的方式,使用不同的模型來處理單一查詢的不同要素,最後再使用一個額外的模型將所有內容整合起來。由於這本質上是多個 AI 模型之間的協作,因此還可以實現某種事實查核系統。
然而,提高準確率並非首要目標。主要目標是降低幻覺率,這意味著我們需要重視「我不知道」的回答,以及包含正確答案的回答。
事實上,我完全不知道OpenAI會怎麼做,也不知道他們的研究人員對幻覺發生率上升究竟有多擔憂。我只知道,幻覺增多對最終用戶不利——這意味著有越來越多的機會在我們不知情的情況下誤導我們。如果你是LLM模型的忠實擁躉,沒必要停止使用它們——但千萬不要因為想節省時間而忽略了核實結果的重要性。務必核實事實!
評論被關閉。