

生成式人工智慧 (GenAI) 正在快速發展,不再僅限於有趣的聊天機器人或令人印象深刻的影像生成。 2025 年,人們的關注點將轉向如何將媒體對人工智慧的炒作轉化為真正的價值。各行各業的公司都在尋求將 GenAI 整合到其產品和流程中的方法,以更好地服務用戶、提高效率、保持競爭力並推動成長。由於領先供應商提供的 API 和預訓練模型,整合 GenAI 似乎比以往任何時候都更容易。但問題在於: 整合容易並不代表人工智慧解決方案部署後就能如預期運作。

預測模型其實並不新鮮:身為人類,我們預測事物已有多年歷史,正式起源於統計學。然而, GenAI從多方面革新了預測領域。:
- 你不需要訓練模型,也不需要成為資料科學家才能建立人工智慧解決方案。
- 現在,人工智慧可以透過聊天介面輕鬆使用,也可以透過應用程式介面(API)輕鬆整合。
- 實現了以前不可能或很難做到的許多事情。
所有這些因素共同作用 基因人工智慧令人無比興奮,但也充滿風險。與傳統軟體甚至經典機器學習不同,GenAI 帶來了更高層次的不可預測性。它並非實現確定性邏輯,而是使用基於海量資料訓練的模型,並寄望它能按需回應。那麼,我們如何判斷人工智慧系統是否如預期運作?如何判斷它是否已準備就緒?答案在於評估,我們將在本文中探討這個概念。
- 為什麼 Genai 系統不能像傳統軟體甚至經典機器學習 (ML) 系統那樣進行測試?
- 為什麼評估對於了解您的人工智慧系統的品質至關重要,而不是可有可無的(除非您喜歡意外情況)
- 不同類型的評估及其在實踐中的應用技巧
無論您是產品經理、工程師,還是任何從事人工智慧工作或對人工智慧感興趣的人,我都希望這篇文章能幫助您了解如何批判性地思考人工智慧系統的品質(以及為什麼評估對於實現這種品質至關重要!)。
生成式人工智慧無法像傳統軟體一樣進行測試,甚至無法像經典機器學習那樣進行測試。
在傳統的軟體開發中系統遵循確定性邏輯: 如果X發生,那麼Y就會發生。 ——始終如此。除非你的平台出現故障或你的程式碼中引入了錯誤…這就是為什麼測試、監控和警報必不可少。單元測試用於驗證小塊程式碼,整合測試用於確保組件協同工作,監控用於檢測生產環境中是否存在故障。測試傳統軟體就像檢查計算器。你輸入 2 + 2,期望結果是 4。清晰明了,結果非真即假。
然而,機器學習和人工智慧引入了不確定性和機率。我們不再透過規則明確定義行為,而是訓練模型從資料中學習模式。 在人工智慧中,如果 X 發生,輸出不再是靜態編碼的 Y,而是基於模型在訓練期間學習到的內容,以一定機率進行的預測。這雖然非常強大,但也引入了不確定性:相同的輸入隨著時間的推移可能會產生不同的輸出,看似合理的輸出實際上可能是錯誤的,而且在罕見的情況下可能會出現意想不到的行為…
這使得傳統的測試方法顯得不足,有時甚至不可行。計算器的例子類似於評估學生在開放式考試中的表現。對於每個問題,以及眾多可能的答案,提供的答案是否正確?是否超越了學生應有的知識水準?學生是否完全捏造了答案,但看起來卻非常有說服力?就像考試中的答案一樣, 人工智慧系統可以進行評估,但它們需要一種更通用、更靈活的方法來適應不同的輸入、環境和用例。 (或測試類型)。
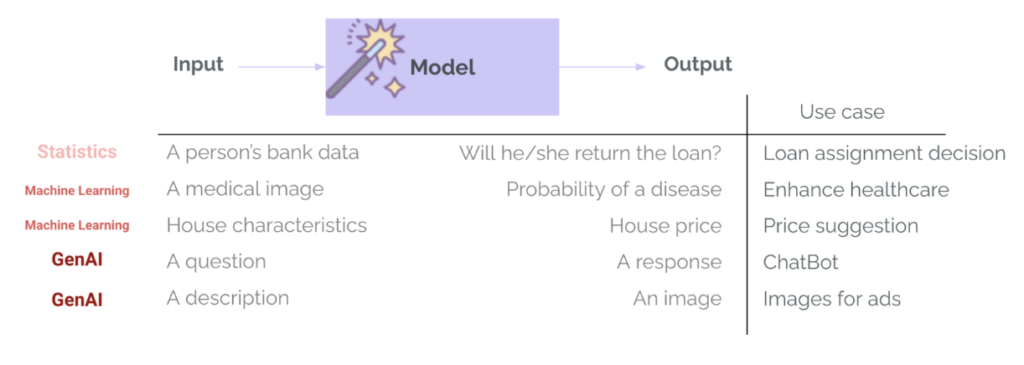
في 機器學習 傳統上(ML),評估已經是專案生命週期中一個成熟的組成部分。訓練用於特定任務(例如貸款審批或疾病檢測)的模型總是包含評估步驟——使用準確率、召回率、均方根誤差 (RMSE) 和平均絕對誤差 (MAE) 等指標。這用於衡量模型的性能,比較不同的模型方案,並確定模型是否足夠好到可以部署。在 GenAI,情況通常有所不同:團隊使用的是已經由模型提供者內部訓練並通過通用評估以及在通用基準測試中表現優異的模型。這些模型非常擅長回答問題或撰寫電子郵件等通用任務,因此存在過度依賴它們來滿足我們特定用例的風險。然而,重要的是要問…這款性能卓越的模型是否足以滿足我的使用需求?“這就需要進行評估了。” - 評估預測或產生結果是否適用於特定用例、上下文、輸入和使用者。

機器學習 (ML) 和全像人工智慧 (GenAI) 之間的另一個主要區別在於模型輸出的多樣性和複雜性。我們不再返回類別和機率(例如客戶償還貸款的機率)或數字(例如基於房屋特徵的預測價格)。全息人工智慧系統可以傳回多種類型的輸出,這些輸出的長度、語氣、內容和格式各不相同。同樣,這些模型不再需要高度結構化和特定的輸入,而是通常接受幾乎任何類型的輸入——文字、圖像,甚至是音訊或視訊。因此,評估變得更加複雜。
為什麼評估是必要的而不是可選項(除非你喜歡意想不到的不愉快結果)?
評估流程可以幫助您衡量您的人工智慧系統是否真正如預期運作。 你想要它系統是否已準備就緒,如果已準備就緒,是否能持續如預期運作。以下分析闡述了評估流程的重要性:
- 品質評估: 評估流程提供了一種結構化的方法,幫助您了解人工智慧預測或輸出的質量,以及它們如何融入整個系統和用例。這些響應是否準確?是否有幫助?是否連貫一致?是否相關?
- 確定誤差數量: 評估有助於確定錯誤的百分比、類型和嚴重程度。錯誤發生的頻率如何?哪些類型的錯誤經常發生(例如,誤報、幻覺、格式錯誤)?
- 風險緩解: 它可以幫助您在有害或帶有偏見的行為影響用戶之前發現並阻止這些行為,從而保護您的公司免受潛在的聲譽、道德和監管風險的影響。
生成式人工智慧憑藉其自由的輸入輸出關係和長文本生成能力,使得評估變得更加重要和複雜。一旦出錯,後果可能不堪設想。我們都曾經看過這樣的新聞:聊天機器人提供危險建議,模型產生帶有偏見的內容,以及人工智慧工具憑空捏造謊言。
“人工智慧永遠不會完美,但透過使用評分,您可以降低尷尬的風險——這可能會讓您損失金錢、信譽,或在 Twitter 上引發病毒式傳播。“
如何定義人工智慧評估策略?

那麼,我們該如何定義人工智慧評估呢?並沒有一成不變的方法。評估取決於具體的應用場景,並且應該與人工智慧應用的既定目標保持一致。例如,如果您正在建立搜尋引擎,您可能會關注搜尋結果的相關性。如果是聊天機器人,您可能會關注它的實用性和安全性。如果是排名系統,您可能更專注於準確性和精確度。對於涉及多個步驟的系統(例如,一個人工智慧系統執行搜尋、對結果進行優先排序,然後產生答案),通常需要單獨評估每個步驟。這樣做的目的是衡量每個步驟是否對實現整體成功指標有所貢獻(並由此了解迭代和改進的重點應該放在哪裡)。
常見的評估領域包括:
- 正確性與幻覺: 輸出結果是否真實且準確?系統是否會產生錯誤訊息或產生幻覺?
- 關聯: 內容是否與使用者的查詢或提供的上下文一致?
- 安全性、偏見和毒性
- 格式: 輸出格式是否符合預期(例如,JSON、有效的函數呼叫)?
- 安全性、偏見和毒性: 該系統是否會產生有害、偏見或有毒的內容?
任務特定指標。 例如,在分類任務中,使用準確率和精確率等指標;在摘要任務中,使用 ROUGE 或 BLEU 指標;在程式碼建立任務中,檢查正規表示式和無錯誤執行情況。
評估結果(Evals)究竟是如何計算的?
確定要測量的指標後,下一步就是設計測試案例。測試案例是一系列範例(範例越多越好,但始終要權衡價值和成本),其中包含:
- 輸入範例系統進入生產階段後,對其進行切合實際的介紹。
- الناتج المتوقع (如果可能):基本事實或預期結果的例子。
- 評價方法: 用於評估結果的評分機制。
- 結果或成功/失敗一個用於評估您測試狀態的計算量表。
根據您的需求、時間和預算,您可以使用以下幾種評估方法:
- 統計記錄工具,例如 BLEU、ROUGE 和 METEOR,或測量嵌入之間的餘弦相似度-適用於將產生的文字與參考輸出進行比較。
- 傳統的機器學習指標,例如 準確率、召回率和 AUC – 最適合使用標記資料進行分類。
- 大型語言模型作為評審團(LLM-as-a-Judge) 使用大規模語言模型來評估輸出結果(例如,“這個答案是否正確且有幫助?當沒有分類資料或評估開放式作品時,這尤其有用。
基於代碼的評估過程 使用標準表達式、邏輯規則或實作測試案例來驗證格式。
底線
讓我們用一個具體的例子來把所有內容連結起來。假設你正在建立一個情緒分析系統,以幫助你的客戶支援團隊確定收到的電子郵件的優先順序。
目標是確保最緊急或最負面的訊息能夠得到更快的回應——從而減少客戶的挫折感,提高他們的滿意度,並降低客戶流失率。這是一個相對簡單的用例,但即使在像這樣輸出有限的系統中,品質也至關重要:預測不準確會導致郵件優先順序隨意分配,這意味著您的團隊在浪費時間在一個需要付費的系統上。
那麼,如何確定你的解決方案是否如預期運作呢?你需要進行評估。以下是一些可能與此特定用例相關的評估範例:
- 格式驗證: 大型語言模型(LLM)呼叫電子郵件情緒預測的輸出是否以預期的JSON格式傳回?這可以透過基於程式碼的檢查來評估:正規表示式驗證、模式驗證等。
- 情感分類準確率: 該系統能否正確辨識各種文本(短文本、長文本和多語言文本)中的情緒?這可以透過使用傳統機器學習指標(ML指標)分類的數據進行評估;或者,如果沒有分類數據,則可以使用大型語言模型(LLM)作為評判標準。
一旦解決方案變得簡單明了,你還需要納入與解決方案的最終影響最相關的指標。:
- 優先排序有效性: 客服人員是否真的被安排處理最重要的郵件?優先排序是否符合預期對業務的影響?
- 最終業務影響: 隨著時間的推移,該系統能否縮短回應時間、降低客戶流失率並提高滿意度評分?
評估對於確保建置的人工智慧 (AI) 系統有用、安全、有價值且可供生產用戶使用至關重要。 因此,無論您使用的是簡單的分類器還是開放式的聊天機器人,都要花時間定義「足夠好」(最低可接受的品質)的含義,並圍繞它建立評估來衡量它!
審稿人
[1] 您的AI產品需要評估哈梅爾·侯賽因
[2] 法學碩士(LLM)評估指標:終極法學碩士評估指南,自信人工智慧
[3] 評估人工智慧代理,deeplearning.ai + Arize
評論被關閉。