

使用 Ollama 對基於 GPQA 的 DeepSeek-R1 模型進行效能評估,並採用 OpenAI 的簡單評估方法進行驗證。
在本地提煉的 DeepSeek-R1 模型上設定並執行標準的 GPQA-Diamond 測試,以評估其推理能力。
最新車型發布 DeepSeek-R1 它在全球人工智慧界引起了廣泛共鳴。它所取得的突破性進展可與 Meta 和 OpenAI 的推理模型相媲美,而且耗時更短,成本也低得多。
但拋開新聞標題和網路媒體的炒作,我們如何使用公認的標準來評估模型的推理能力呢?這對人工智慧專家來說是一個重要的問題。
。 用戶界面 深度搜尋 它使探索其功能變得更加容易,但以程式設計方式使用它則能提供更深入的洞察,並能更順暢地整合到實際應用中。了解這些模型在本地的運作方式還能增強控制力並支援離線存取。

在本文中,我們將探討如何使用 奧拉馬 和 來自 OpenAI 的簡單評估 為了評估基於標準的 DeepSeek-R1 蒸餾模型的推理能力 GPQA-鑽石級 這個著名標準被認為是評估邏輯推理領域人工智慧模型的最重要工具之一。
給你 GitHub 倉庫鏈接 本文的姊妹篇。
(1)推理模型有哪些?
推理模型,例如 DeepSeek-R1 和 OpenAI 的 o 系列模型(例如 o1、o3),是使用強化學習訓練的大型語言模型 (LLM),用於執行推理任務。這些模型被認為是人工智慧領域的尖端工具,代表了機器學習的巔峰水平,以及進行邏輯推理和解決複雜問題的能力。
推理模型的特點是會在回答問題前深入思考,產生一系列內在思考過程後再做出回應。它們擅長解決複雜問題、程式設計、科學推理以及多步驟智能體工作流程規劃。這些能力使它們在高級軟體開發、科學研究和複雜流程自動化等領域不可或缺。
(2)什麼是 DeepSeek-R1 模型?
DeepSeek-R1 是一款最先進的開源大型語言模型 (LLM),專為…而設計。 高級推理該研究論文於2025年1月發表。 “DeepSeek-R1:透過強化學習激發大型語言模型的推理能力“DeepSeek-R1 被認為是人工智慧領域的開創性模型。
該模型基於具有 671 億個參數的大型語言模型 (LLM) 架構,並使用以下路徑的強化學習 (RL) 進行訓練:
- 強化訓練分為兩個階段,旨在發現改進的推理模式並符合人類的偏好。
- 兩個階段的監督式微調為模型的推理能力和非推理能力奠定了基礎。
例如,DeepSeek 訓練了兩個模型:
- 第一款模型, DeepSeek-R1-Zero這是一個使用強化學習訓練的推理模型,它產生資料來訓練第二個模型。 DeepSeek-R1.
- 這是透過產生推理軌跡來實現的,根據最終結果,只保留高品質的輸出。
- 這意味著,與大多數模型不同,此訓練路徑中的強化學習 (RL) 範例不是由人類協調的,而是由模型本身創建的。
結果表明,該模型達到了與領先模型類似的性能,例如: OpenAI 模型 o1 在數學、程式設計和複雜推理等任務中。
(3)了解DeepSeek-R1的蒸餾過程和餾出物樣品
除了完整模型外,他們還開放了六個更小、更密集的模型(也稱為 DeepSeek-R1)的原始碼,這些模型大小各異(1.5 億、7 億、8 億、14 億、32 億、70 億),是基於 DeepSeek-R1 提煉而來。 奎文 أ或者 駱駝 作為基本模型。
蒸餾 這是一種訓練較小模型(「學生」)來複製先前訓練過的更大、更強大的模型(「教師」)表現的技術。
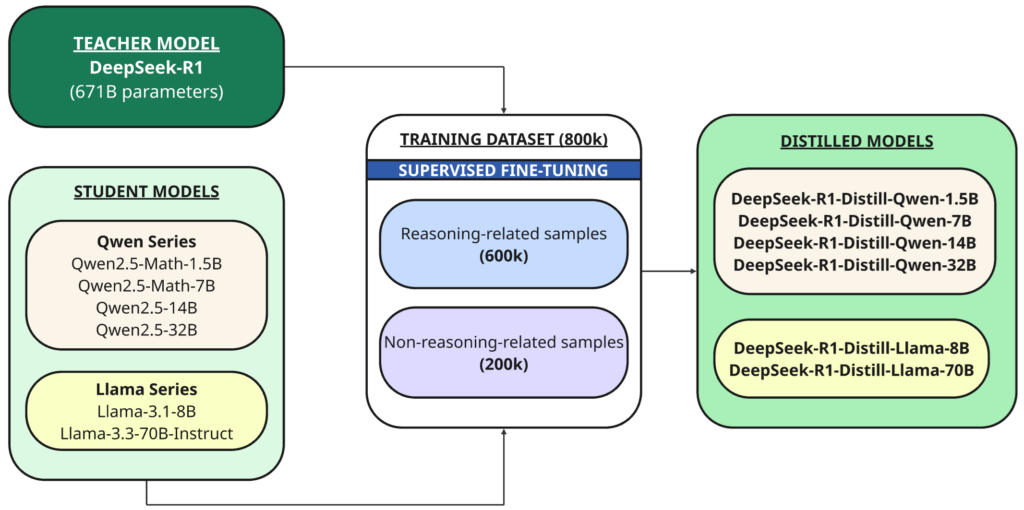
在這種情況下,教師是一個大小為 671B 的 DeepSeek-R1 模型,學生是使用此開源基礎模型提煉出的六個模型:
DeepSeek-R1 被用作教師模型,產生了 800,000 個訓練樣本,包括推理樣本和非推理樣本,用於交叉引用。 監督式微調 適用於基本型號(1.5B、7B、8B、14B、32B 和 70B)。
那麼,我們為什麼要進行蒸餾呢?
目標是將大型模型(例如 DeepSeek-R1 671B)的推理能力轉移到更小、更有效率的模型上。這使得小型模型能夠處理複雜的推理任務,同時速度更快、資源利用率更高。
此外,DeepSeek-R1 包含大量參數(671 億),這使得大多數消費級設備難以運作。
即使是效能最強的 MacBook Pro,最大記憶體可達 128GB,也無法運作參數高達 671 億的機型。
這樣一來,精簡模型就有可能部署在運算資源有限的裝置上。
達到 不懶惰 這是一項卓越的成就,他們將擁有 671 億個參數的原始 DeepSeek-R1 模型量化到僅 131GB,體積大幅縮減了 80%。然而,131GB 的顯存需求仍然是一個主要障礙,尤其對於在資源受限硬體上工作的開發者。這項成就標誌著大型 AI 模型在惠及更廣泛的用戶群方面邁出了重要一步。
(4)選擇最優餾出物模型
有六種不同尺寸的滴注型號可供選擇,確定合適的型號很大程度上取決於當地設備的性能。
對於擁有高性能 GPU 或 CPU 且需要最大效能的用戶來說,更大的 DeepSeek-R1 型號(32B 以上)是理想之選——即使是量子版本 671B 也是可行的。
然而,如果資源有限或您更傾向於更快的構建速度(就像我一樣),那麼較小的精簡版本,例如 8B 或 14B,則是更好的選擇。這樣可以在效能和資源需求之間取得平衡。
在這個專案中,我將使用 DeepSeek-R1 精煉模型。 Qwen-14B這與我遇到的設備的限制相符。 這款型號(14B)在精度和速度之間取得了很好的平衡,非常適合我的開發環境。
(5)大型語言模型推理能力評估標準
大型語言模型(LLM)通常使用標準化標準進行評估,這些標準用於確定其在各種任務中的表現水平,包括語言理解、程式碼產生、指令執行和問答。常見的例子包括以下指標: 百萬美元وو 人類評估وو 行動行動通訊系統這些指標對於評估大型語言模型的能力至關重要。
為了衡量大型語言模型的邏輯推理能力,我們需要更具挑戰性的標準,這些標準應側重於推理本身,而不僅限於表面任務。以下是一些專注於評估高階推理能力的常見範例:
(i)2024年AIME考試:競爭性數學
- 準備 2024年美國數學邀請賽(AIME) 評估大型語言模型(LLM)數學推理能力的強大標準。
- 這項考試在數學競賽中極具挑戰性,它提出的問題是複雜的、多步驟的。它測試大型語言模型理解複雜問題、運用高階推理以及精確符號運算的能力。 AIME 被認為是衡量解決複雜數學問題能力的重要指標。
(二)Codeforces – 競賽規則
- 起床 Codeforces 標準 透過評估大型語言模型 (LLM) 在 Codeforces 平台上的真實世界競技程式設計問題上的推理能力,Codeforces 是一個以演算法挑戰而聞名的平台。 Codeforces 被認為是評估人工智慧模型解決複雜問題能力的黃金標準。
- 這些問題旨在測試大型語言模型(LLM)理解複雜指令、進行邏輯和數學推理、規劃多步驟解決方案以及產生正確高效程式碼的能力。這些問題要求對演算法和資料結構有深入的理解,並且能夠將問題轉化為可執行程式碼。
(三)GPQA 鑽石-博士級的科學問題
- GPQA-Diamond 是選定的子集 最難的問題 從標準 GPQA(研究生物理問答) 此標準範圍最廣,旨在突破LLM模型在高階博士級課題中推斷意義的能力極限。這項標準對人工智慧理解和推論複雜科學概念的能力提出了真正的挑戰。
- 雖然 GPQA 包含了一系列依賴計算過程的概念性研究生水平問題,但 GPQA-Diamond 只選取了最具挑戰性的問題和需要深入推理的問題。
- 這項標準被認為是「抗谷歌搜尋」的,也就是說,即使擁有不受限制的網路存取權限,也很難回答。這使其成為評估大型語言模型獨立思考能力的重要工具。
- 以下是一個 GPQA-Diamond 問題的範例:
### GPQA 鑽石題 - 範例題(分子生物學)真核細胞演化出一種將大分子建構單元轉化為能量的機制。這個過程發生在粒線體中,粒線體是細胞的能量工廠。在一系列氧化還原反應中,食物中的能量儲存在磷酸基團之間,並作為細胞的通用貨幣。這些富含能量的分子被運送出粒線體,用於所有細胞過程。你發現了一種新的抗糖尿病藥物,並想研究它是否對粒線體有影響。你利用 HEK293 細胞系設計了一系列實驗。下列哪項實驗無法幫助你發現藥物的粒線體作用:(A)差速離心提取粒線體,然後使用葡萄糖攝取比色法檢測試劑盒;(B)用 2.5 µM 5,5',6,6'-四氯-1,1',3,3'-四乙基苯並咪唑基碳菁化物標記後進行流式碘化物標記後進行螢光細胞轉化法(C µC)。螢光素後進行發光儀讀數;(D)以 Mito-RTP 染色細胞後進行共聚焦螢光顯微鏡觀察。
在這個項目中, 我們使用 GPQA-Diamond 作為推理的基準。我也用過它 OpenAI 和 深度搜尋 為了評估它們的推理模型。選擇 GPQA-Diamond 作為評估標準,證明了它在人工智慧開發領域的困難和重要性。
(6)使用的工具
在這個專案中,我們主要使用 奧拉馬 和 簡單評估 來自 OpenAI。 Ollama 是一個功能強大的平台,用於在本地運行大型語言模型,而 simple-evals 則提供了一個用於評估這些模型性能的框架。
(i)美洲駝
奧拉馬 Olama 是一款開源工具,可簡化在電腦或本機伺服器上執行大型語言模型 (LLM) 的過程。它是本地運行 AI 模型的理想平台。
它充當管理員和運行時環境的角色,處理下載和環境設定等任務。這使得用戶無需持續的網路連線或依賴雲端服務即可與這些模型互動。管理原生大型語言模型 (LLM) 是 Olama 的核心功能之一。
它支援眾多大型開源語言模板,包括 DeepSeek-R1,並且跨平台兼容 macOS、Windows 和 Linux。此外,它設定簡便,資源利用率高。 Ollama 軟體讓您直接在裝置上運用人工智慧的強大功能。
重要的請確保您的本機設備已具備以下條件: 圖形處理單元 (GPU) 的可存取性 對於 Ollama 來說,這顯著提升了效能,並使後續的基準測試比使用 CPU 更有效率。運行該命令。
nvidia-smi在終端機中,檢查是否偵測到圖形處理單元 (GPU)。此步驟可確保充分利用設備的效能來有效運作模型。
(ii)OpenAI simple-evals 函式庫,用於評估語言模型
準備 簡單評估 這是一個輕量級函式庫,旨在透過零樣本方法和心智圖提示來評估語言模型。該程式庫整合了 MMLU、MATH、GPQA、MGSM 和 HumanEval 等常用評估標準,並致力於模擬真實世界的用例,以評估人工智慧模型在複雜推理任務中的效能。
你們當中有些人可能熟悉 OpenAI 最受歡迎、最全面的評估庫,它叫做 評價它與簡單求值不同。
事實上,該頁面表明 自述 simple-eval 的具體特性表明它並非旨在取代庫。 評價.
那麼,我們為什麼要使用簡單求值呢?
簡單的答案是: 簡單評估 它內建了針對我們所針對的推理標準(例如 GPQA)的評估文本,而圖書館則缺少這些文本。 評價.
此外,除了 simple-evals 之外,我還沒有找到任何其他工具或平台可以提供該語言的直接原生方法。 蟒蛇 運行許多關鍵標準,例如 GPQA,尤其是在使用 Ollama 時。
(7)評估結果
作為評估的一部分,我選擇了 20個隨機問題 這是 GPQA-Diamond 題庫中的題目,共有 198 題供他練習。 蒸餾模型 14B總共花時 216 分鐘,平均每題約 11 分鐘。
結果有點令人失望,因為記錄顯示 10% 只是,這明顯低於 DeepSeek-R1 模型(大小為 671B)報告的 73.3% 的結果。
我注意到的主要問題是,在進行深入的內部推理時, 該模型經常要么無法產生任何答案(例如,返回推理標記作為最終輸出行),要么提供的響應與預期的多項選擇格式不符(例如,答案:A)。
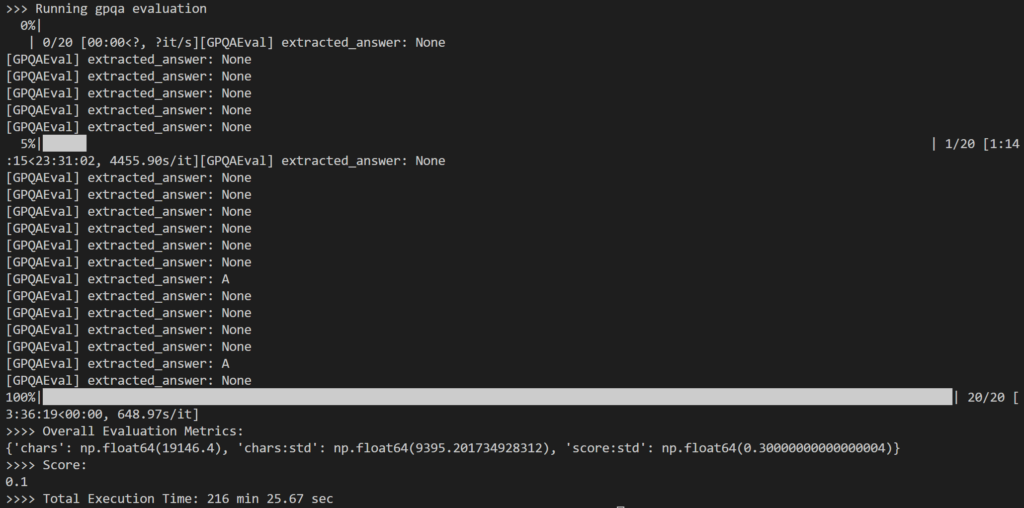
如上所述,許多輸出結果最終如下所示: None 因為 simple-evals 中的正規表示式邏輯無法偵測到 LLM 回應中的預期回應模式。
雖然那 類人推理 觀察結果很有意思,因為我原本預期他們在回答問題的準確率方面會有更好的表現。
我還看到一些網路使用者提到,即使是更大的 32B 模型,其效能也不如 o1 模型。這引發了人們對精簡推理模型實用性的質疑,尤其是在它們產生冗長的推理過程卻難以提供正確答案的情況下。
然而,GPQA-Diamond 標準非常複雜,因此這些模型對於較簡單的推理任務仍然有用。它們較低的計算需求也使它們更容易使用。
此外,DeepSeek 團隊建議在測量過程中進行多次取平均值的測試——由於時間限制,我忽略了這一點。
(8)詳細的分步指南
至此,我們已經介紹了基本概念和主要結論。
如果您準備好體驗實際操作和技術操作,本節將深入剖析內部機制並提供逐步實施指南。這份實用的技術指南將幫助您全面了解系統的工作原理。
查看(或複製) 配套的 GitHub 倉庫 繼續。虛擬環境設定要求請參閱此處。 這裡.
(i)初步準備-奧拉瑪
我們先來下載 Ollama。請訪問
Ollama 下載頁面選擇您的作業系統並按照相應的安裝說明進行操作。
安裝完成後,請雙擊 Ollama 應用程式(適用於 Windows 和 macOS)或執行命令即可啟動 Ollama。 ollama serve 在終端單元中。
(二)初始設定-OpenAI 簡單評估
設定簡單評估是相對獨特的。
雖然 simple-evals 以庫的形式呈現, 文件缺失 __init__.py 在程式碼庫中,這意味著它沒有被組織成一個合格的 Python 套件。這會導致在本地克隆倉庫後出現導入錯誤。這意味著它並非傳統意義上的Python標準套件。
因為它也沒有發佈在 PyPI 上,並且缺少標準打包文件,例如: setup.py أ或者 pyproject.toml它無法透過以下方式安裝 pip這使得新手開發者面臨一定的挑戰。
幸運的是,我們可以利用 Git 子模組 作為直接的替代方案,這些模組可讓您將一個 Git 儲存庫嵌入到另一個 Git 儲存庫中,從而簡化依賴關係管理。
「`html
Git 子模組讓我們可以將另一個 Git 倉庫的內容包含到我們的專案中。它會從外部倉庫(例如 simple-evals)拉取文件,但會保持其歷史記錄的獨立性。
您可以選擇以下兩種方法之一(A 或 B)來檢索 simple-eval 的內容:
(a) 如果我複製我的專案倉庫
我的專案倉庫中已經包含 simple-evals 作為子單元,因此您只能運行:
git submodule update --init --recursive(b)如果您要將其新增至新建的專案中
若要手動新增 simple-evals 作為子單元,請執行下列命令:
git submodule add https://github.com/openai/simple-evals.git simple_evals筆記: 那 simple_evals 最後(與 下級警察這一點極為重要。它指定了資料夾名稱,不建議使用連字符代替(即,直接使用)。 - 評估)可能會導致後續導入出現問題。
最後一步(兩種方法均適用)
從倉庫提取貨物後,您必須建立一個文件 __init__.py 資料夾中為空 simple_evals 這個新建立的模組可以導入。您可以手動創建,也可以使用以下命令:
touch simple_evals/__init__.py(三)透過 Ollama 拉取 DeepSeek-R1 模型
下一步是使用以下命令將您選擇的餾分油模型(例如,14B)下載到本地:
您可以在 Ollama 上找到可用的 DeepSeek-R1 型號清單。 這裡為了獲得最佳性能,建議使用該模型的最新版本。
ollama pull deepseek-r1:14b(第四)設定
我們在 YAML 設定檔中定義參數,如下所示:
# config/config.yaml MODEL_NAME: "deepseek-r1:14b" # 模型名稱(與 Ollama 模型清單匹配) MODEL_TEMPERATURE: 0.6 # DeepSeek-R1 的溫度值應介於 0.5 和 0.7 之間 EVAL_BENCARKARK: "gpd:"QAQA
模型溫度設定為 0.6 (與典型的預設值 0 相比)。這符合 DeepSeek 的使用建議,建議溫度範圍為 0.5 到 0.7(建議為 0.6)。 防止無限重複或輸出不連貫的內容。 這種設定對於提高輸出品質和確保其一致性至關重要。
不要錯過這次機會! 獨特而有趣的 DeepSeek-R1 使用建議 – 尤其是在標準參數方面 – 以確保在使用 DeepSeek-R1 模型時獲得最佳性能。
EVAL_N_EXAMPLES 此參數用於指定評估中使用的題目數量,評估題目總數為198道。此參數對於根據可用資源和既定測試目標調整評估流程至關重要。
(五)設定採樣器程式碼(採樣工具)
為了在 simple-evals 框架中支援基於 Ollama 的語言模型,我們創建了一個名為 的自訂包裝類 OllamaSampler 把它放在裡面 utils/samplers/ollama_sampler.py採樣工具(Sampler)是測試和評估語言模型效能的重要組成部分。
# utils/samplers/ollama_sampler.py import ollama class OllamaSampler: def __init__(self, model_name=None, temperature=0): self.model_name = model_name self。 prompt_messages[-1]["content"] response = ollama.chat( model=self.model_name, messages=[{"role": "user", "content": prompt_text}], options={"temperature": self.temperature} ) response"contentmesage" response" 4. response_content def _pack_message(self, content, role): return {"role": role, "content": content}
在此語境下,其意義是: 取樣器 (採樣)一個 Python 類,它根據特定的提示,利用語言模型產生輸出。該工具對於確保模型產生多樣化且具代表性的響應至關重要。
由於 simple-evalus 中的採樣工具僅支援 OpenAI 和 Cloud 等供應商,我們需要一個提供與 Ollama 相容介面的採樣器類別。這可以確保與評估框架的無縫整合。
起床 OllamaSampler 透過擷取 GPQA 查詢提示,將其以指定的溫度傳送到表單,並傳回純文字回應,溫度是控制輸出隨機性的關鍵參數。
方法包括 _pack_message 為確保輸出格式與 simple-evals 中的評估文字預期一致,從而保證了一致性並便於分析。
6. 建立一個腳本來執行評估。
以下程式碼示範如何在文件中設定評估實作。 main.py這包括使用該類別 GPQAEval 使用 simple-evals 函式庫執行標準 GPQA 測試。
功能 run_eval() 這是一個可配置的評估驅動程序,它透過 Ollama 對大型語言模型 (LLM) 進行測試,測試標準包括 GPQA 等。此功能對於準確評估模型效能至關重要。
# main.py def run_eval(): start_time = time.time() # 載入設定檔 config = load_config("config/config.yaml") # 初始化 Ollama 取樣器(Ollama chat 的封裝) ollama_sampler = OllamaSampler(model_Dconfig," ? "n_repeats": config["EVAL_N_REPEATS"], # 預設值 1 "num_examples": config["EVAL_N_EXAMPLES"], # 設定為 20 "variant": config["GPQA_VARIANT"], # GPQA-DiaARK Errg-DiaARKgol UelseARK(Errr:Dia REr:DiaARK Error(Err:Dia) '{eval_benchmark}'." ) # 實例化並執行對應的評估 evaluator = eval_class(**eval_kwargs) results = evaluator(ollama_sampler) # 使用取樣器執行評估 end_time = time.time() elapsed_seconds = ends_time - _seconds =seconds_seconds 60) # 計算總耗時 # 傳回的結果是一個 EvalResult,其中包含 SingleEvalResult 清單和聚合指標 print(">>>> 總體評估指標:", results.metrics) print(">>>>> 分數:", results.score) print(f">> 執行時間點: 執行時間}. __name__ == "__main__": # 執行 GPQA 評估執行 run_eval()
此函數從設定檔載入設置,從 simple-evals 中配置合適的評估類,並執行模型執行標準化的評估流程。評估結果保存到一個文件中。 main.py可以使用以下命令執行 python main.py這樣可以確保評估過程的一致性和可重複性。
按照上述步驟,我們已成功在 DeepSeek-R1 精煉模型上設定並執行了 GPQA-Diamond 基準測試。此過程為我們深入了解模型的性能提供了寶貴的資訊。
底線
在本文中,我們探討如何結合 Ollama 和 OpenAI 的 simple-evals 等工具來探索和評估 DeepSeek-R1 精簡模型,重點關注… 評估大型語言模型的效能.
精簡後的模型在滿足 GPQA-Diamond 等高要求推理標準方面,可能還無法與原始的 671 億參數模型相提並論。然而,它們展示了精簡如何擴展大型語言模型 (LLM) 的推理能力。 改善對大型語言模型的訪問 這是該領域的主要目標。
儘管在複雜的博士級任務中結果較低,但這些小型變體在要求不高的場景下仍然可行,從而為在更廣泛的設備上更高效地進行本地部署鋪平了道路。這有助於… 發布大型語言模型 高效。
評論被關閉。