

人工智慧代理的潛力已經席捲全球。代理商可以與周圍的世界互動,撰寫文章(但不包括本文),代表你採取行動,並且通常可以使自動化任何任務中困難的部分變得簡單易行。
智能體專注於流程中最棘手的部分,並快速處理問題——有時甚至過快。如果你的智能體驅動流程需要人工參與來決定結果,那麼人工審核階段就可能變成瓶頸。
代理驅動流程的一個例子是處理和分類客戶來電。即使是準確率高達 99.95% 的代理,在監聽 10,000 通電話時也會犯 5 個錯誤。儘管他們知道這一點,但他們無法告知您。 哪一個 每10,000通電話中有5通被錯誤分類。

「LLM作為評判者」技術是指將每個輸入輸入到另一個LLM過程中,以評估該輸入的輸出是否正確。然而,由於這是另一個LLM過程,因此其結果也可能不準確。這兩個機率過程會產生一個混淆矩陣,其中包含真陽性和假陰性,以及真陰性和假陽性。
換句話說,LLM 流程正確分類的參賽作品可能會被 LLM 評審員判定為錯誤,反之亦然。
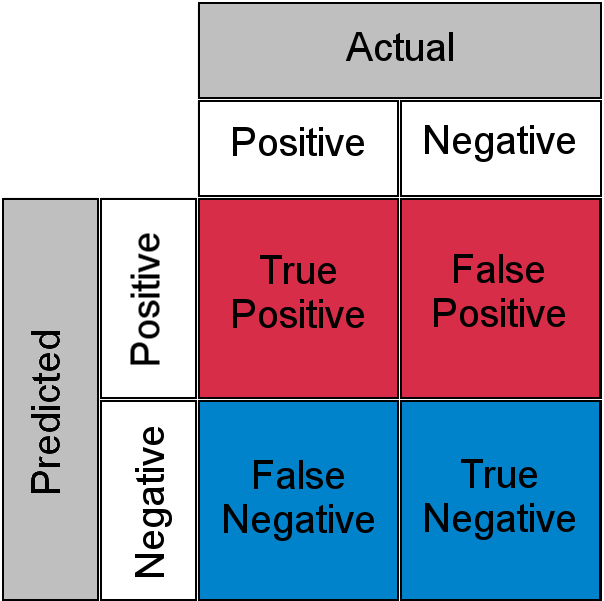
因為這 ” 未知的已知 “對於如此敏感的工作量,一個人必須審查並理解全部10,000通電話。我們又回到了同樣的瓶頸問題。”
如何提高智能體驅動流程的統計確定性?本文建構了一個系統,旨在提高智能體驅動流程的確定性,並將其推廣到隨機數量的智能體,同時開發了一個成本函數,以指導未來對該系統的投資。本文使用的程式碼已發佈在我的程式碼倉庫中。 人工智慧決策迴路.
人工智慧決策迴路
錯誤檢測和糾正並非新概念。錯誤糾正在數位和類比電子等領域至關重要。即使是量子運算的進步也依賴於不斷增強的錯誤修正和檢測能力。我們可以從這些系統中汲取靈感,並利用人工智慧代理實現類似的功能。例如,[可以添加以下內容]。 人工智慧演算法 先進技術利用通訊系統中的糾錯技術。
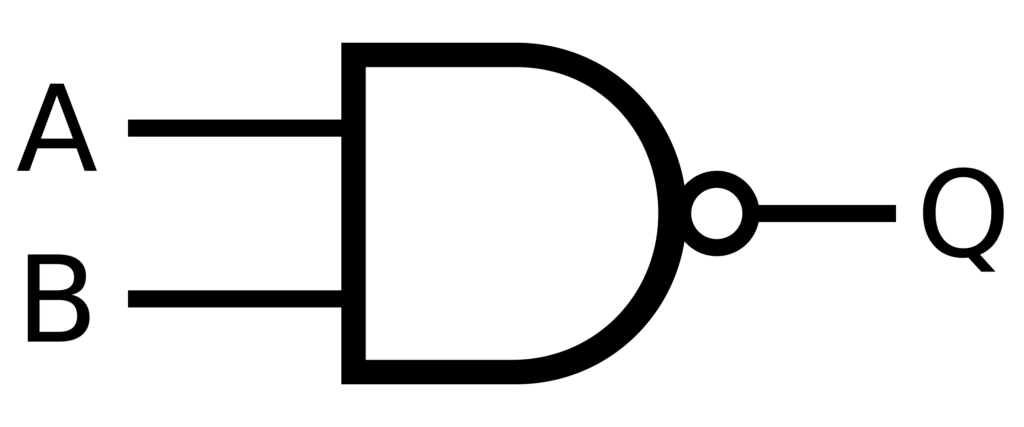
在布林邏輯中,與非閘被視為計算的聖杯,因為它們可以執行任何運算。它們功能完備,這意味著任何邏輯運算都可以僅使用與非閘建置。這項原理可以應用於人工智慧系統,以創建具有內建糾錯功能的穩健決策結構。這使得創建… 神經網路 更可靠,更能處理不完整或失真的數據。
從電子電路到智慧決策(AI)電路
就像電子電路利用迭代和驗證來確保計算的可靠性一樣,智慧決策(AI)電路可以利用具有不同視角的多個智能體來獲得更準確的結果。這些電路可以基於資訊理論和布林邏輯的原理來建構。
- 冗餘處理: 許多人工智慧代理獨立處理相同的輸入,類似於現代CPU使用迭代電路來檢測硬體錯誤的方式。這一過程提高了人工智慧系統的可靠性。
- 共識機制: 決策結果透過投票系統或加權平均值進行組合,類似於容錯電子設備中的多數邏輯閘。這些機制確保最終決策反映出各主體之間的共識。
- 驗證代理: 專門的AI驗證器會檢查輸出結果的合理性,其工作原理類似於錯誤檢測程式碼,例如: 奇偶校驗位 أ或者 定期複查(大腸直腸癌檢查)這些代理程式降低了做出錯誤決策的可能性。
- 人機協同整合: 在決策過程的關鍵節點進行策略性的人工核查,類似生物系統利用人類監督作為最後一層驗證。這確保了關鍵決策能夠接受人類的評估。
人工智慧決策迴路的數學基礎
利用機率論可以定量地確定這些系統的可靠性。
其中一個因素是故障機率,它來自於對儲存在諸如此類系統中的測試資料集進行一段時間的準確性觀察。 蘭史密斯.

對於準確係數為 90% 的情況,即失效機率, p_1، 1–0.9 是0.1,也就是10%。

兩個獨立操作員對同一輸入同時失敗的機率,等於兩個操作員都操作正確的機率相乘:
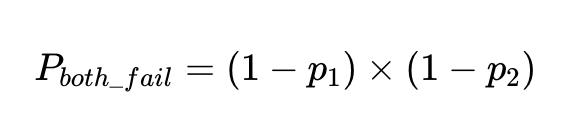
如果我們有 N 個執行程序使用這些客戶端,則總故障數為
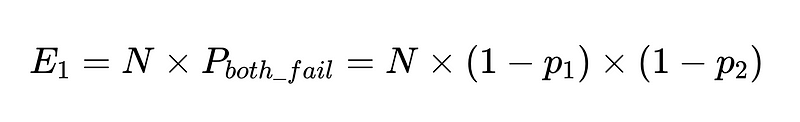
因此,對於兩位獨立操作員之間 10,000 次執行,準確率為 90%,預期失敗次數為 100 次。
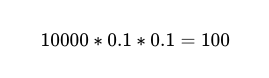
然而,我們仍然不知道 哪一個 在這 10,000 通電話中,有 100 通是實際失敗的。
我們可以將這一理念的四個擴展結合起來,從而提供一個更強大的解決方案,使任何給定的回應都充滿信心:
- 基本分類(以上為簡化版)
- 備份分類(以上為簡化後的準確度)
- 海圖檢查器(例如,精度為 0.7)

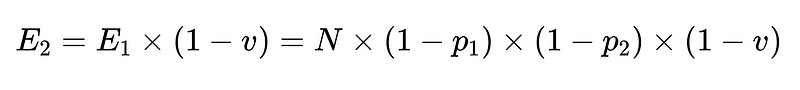
- 最後,使用一個負面驗證器(例如,n = 準確率為 0.6)。
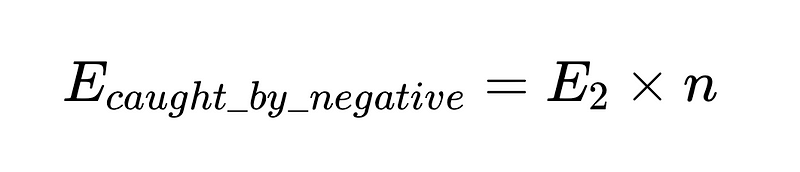
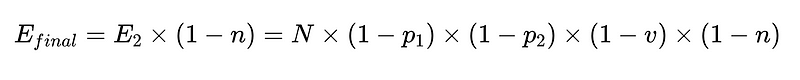
要將此放入程式碼中(完整倉庫我們可以使用 蟒蛇 基本的:
def primary_parser(self, customer_input: str) -> Dict[str, str]:
"""
Primary parser: Direct command with format expectations.
"""
prompt = f"""
Extract the category of the customer service call from the following text as a JSON object with key 'call_type'.
The call type must be one of: {', '.join(self.call_types)}.
If the category cannot be determined, return {{'call_type': null}}.
Customer input: "{customer_input}"
"""
response = self.model.invoke(prompt)
try:
# Try to parse the response as JSON
result = json.loads(response.content.strip())
return result
except json.JSONDecodeError:
# If JSON parsing fails, try to extract the call type from the text
for call_type in self.call_types:
if call_type in response.content:
return {"call_type": call_type}
return {"call_type": None}
def backup_parser(self, customer_input: str) -> Dict[str, str]:
"""
Backup parser: Chain of thought approach with formatting instructions.
"""
prompt = f"""
First, identify the main issue or concern in the customer's message.
Then, match it to one of the following categories: {', '.join(self.call_types)}.
Think through each category and determine which one best fits the customer's issue.
Return your answer as a JSON object with key 'call_type'.
Customer input: "{customer_input}"
"""
response = self.model.invoke(prompt)
try:
# Try to parse the response as JSON
result = json.loads(response.content.strip())
return result
except json.JSONDecodeError:
# If JSON parsing fails, try to extract the call type from the text
for call_type in self.call_types:
if call_type in response.content:
return {"call_type": call_type}
return {"call_type": None}
def negative_checker(self, customer_input: str) -> str:
"""
Negative checker: Determines if the text contains enough information to categorize.
"""
prompt = f"""
Does this customer service call contain enough information to categorize it into one of these types:
{', '.join(self.call_types)}?
Answer only 'yes' or 'no'.
Customer input: "{customer_input}"
"""
response = self.model.invoke(prompt)
answer = response.content.strip().lower()
if "yes" in answer:
return "yes"
elif "no" in answer:
return "no"
else:
# Default to yes if the answer is unclear
return "yes"
@staticmethod
def validate_call_type(parsed_output: Dict[str, Any]) -> bool:
"""
Schema validator: Checks if the output matches the expected schema.
"""
# Check if output matches expected schema
if not isinstance(parsed_output, dict) or 'call_type' not in parsed_output:
return False
# Verify the extracted call type is in our list of known types or null
call_type = parsed_output['call_type']
return call_type is None or call_type in CALL_TYPES將這些過程與邏輯結合起來 布爾 簡而言之,我們可以在保證答案準確性的前提下,實現類似的準確度:
def combine_results(
primary_result: Dict[str, str],
backup_result: Dict[str, str],
negative_check: str,
validation_result: bool,
customer_input: str
) -> Dict[str, str]:
"""
Combiner: Combines the results from different strategies.
"""
# If validation failed, use backup
if not validation_result:
if RobustCallClassifier.validate_call_type(backup_result):
return backup_result
else:
return {"call_type": None, "confidence": "low", "needs_human": True}
# If negative check says no call type can be determined but we extracted one, double-check
if negative_check == 'no' and primary_result['call_type'] is not None:
if backup_result['call_type'] is None:
return {'call_type': None, "confidence": "low", "needs_human": True}
elif backup_result['call_type'] == primary_result['call_type']:
# Both agree despite negative check, so go with it but mark low confidence
return {'call_type': primary_result['call_type'], "confidence": "medium"}
else:
return {"call_type": None, "confidence": "low", "needs_human": True}
# If primary and backup agree, high confidence
if primary_result['call_type'] == backup_result['call_type'] and primary_result['call_type'] is not None:
return {'call_type': primary_result['call_type'], "confidence": "high"}
# Default: use primary result with medium confidence
if primary_result['call_type'] is not None:
return {'call_type': primary_result['call_type'], "confidence": "medium"}
else:
return {'call_type': None, "confidence": "low", "needs_human": True}
決策邏輯:詳細的步驟解說
第一步:當品質控制系統失效時
if not validation_result:這意味著:「如果我們的品質控制專家(審核員)駁回了初步分析,請不要相信他們。」系統隨後會嘗試使用備用意見。如果備用意見也未能驗證分析結果,系統會將該案例標記為需要人工專家複審。此流程確保不會依賴不準確的數據。
簡單來說:「如果我們的第一個答案有問題,我們就試試備用方法。如果備用方法仍然有問題,我們就尋求專家的幫助。」這樣就能確保複雜案例得到正確處理。
步驟二:解決差異
if negative_check == 'no' and primary_result['call_type'] is not None:此步驟檢查某種類型的不一致:“我們的否定驗證器表明不應該存在某種期權類型,但我們的基本面分析師還是發現了一種類型。”
在這種情況下,系統會依賴備用分析器來打破僵局:
- 如果備份分析員認為沒有通話類型,則將其發送給人工處理人員。
- 如果儲備分析師同意首席分析師的意見,則接受該決定,但置信度為中等。
- 如果備用分析員的呼叫類型不同,則會將其轉交給手動處理人員。
這類似於這樣說:“如果一位專家說‘無法分類’,而另一位專家卻說可以分類,我們就需要一位專家來做出最終裁決或人工判斷。”這種機制對於確保呼叫類型分類的準確性以及最大限度地減少潛在錯誤至關重要。
步驟三:當專家們達成一致時
if primary_result['call_type'] == backup_result['call_type'] and primary_result['call_type'] is not None:當主分析員和備用分析員獨立得出相同結果時,系統會給予「高置信度」評級——這是最佳情況。這種理想情況發生在多項分析結果完全一致時。
簡單來說:「如果兩位不同的專家使用不同的方法獨立得出相同的結論,我們就可以相當肯定他們的結論是正確的。」這代表了專家共識,是準確性和可靠性的有力指標。
第四步:虛擬化
若以上特殊情況皆不適用,系統將預設採用基礎分析師的分析結果,信賴度為「中等」。如果基礎分析師本身無法確定呼叫類型,系統會將該案例標記出來,交由合格的人工分析師進行審核。
這種方法在減少誤差方面的重要性
這種邏輯有助於建立強大的系統,具體體現在以下幾個方面:
- 減少誤報該系統僅在多種方法結果一致時才給予高度置信度,這大大降低了誤報率。
- 發現矛盾之處當系統的不同部分意見不一致時,要么會降低置信度,要么會將問題上報給人工審核員,以確保不會遺漏任何潛在問題。
- 智慧升級人工審核員只會看到真正需要他們專業知識的案例,這提高了審核過程的效率,減輕了人力資源的壓力。
- 信託指定結果包括系統的置信度,使得後續流程能夠區別對待高置信度結果和中等置信度結果,這對於做出明智的決策至關重要。
這種方法類似於電子學中利用冗餘電路和投票機制來防止錯誤導致系統故障。在人工智慧系統中,這種精心設計的整合邏輯可以顯著降低錯誤率,同時有效地利用人工審核人員,只在他們能發揮最大價值的地方進行審核。這確保了資源最佳化和錯誤減少的同時,從而建立出更可靠、更準確的系統。
例子
2015年,費城水務局發布了 按類別劃分的客戶來電統計資料。 理解客戶來電是客服人員的日常工作之一。與手動逐一監聽客戶來電不同,客服人員可以更快地聆聽、提取資訊並對來電進行分類,以便進行後續的數據分析。對於水資源管理而言,這一點至關重要,因為越早發現關鍵問題,就能越早解決。
我們可以設計一個實驗。我使用大型語言模型(LLM)產生了相關電話通話的虛假文字記錄,方法是提示:“根據以下類別,產生該電話通話的簡短文字記錄:”以下是一些範例,以及完整的可用文件。 這裡:
{
"calls": [
{
"id": 5,
"type": "ABATEMENT",
"customer_input": "I need to report an abandoned property that has a major leak. Water is pouring out and flooding the sidewalk."
},
{
"id": 7,
"type": "AMR (METERING)",
"customer_input": "Can someone check my water meter? The digital display is completely blank and I can't read it."
},
{
"id": 15,
"type": "BTR/O (BAD TASTE & ODOR)",
"customer_input": "My tap water smells like rotten eggs. Is it safe to drink?"
}
]
}現在,我們可以採用更傳統的評估方式來設定實驗,並使用大型語言模型作為評判標準。完整實現方式請點擊此處):
def classify(customer_input):
CALL_TYPES = [
"RESTORE", "ABATEMENT", "AMR (METERING)", "BILLING", "BPCS (BROKEN PIPE)", "BTR/O (BAD TASTE & ODOR)",
"C/I - DEP (CAVE IN/DEPRESSION)", "CEMENT", "CHOKED DRAIN", "CLAIMS", "COMPOST"
]
model = ChatAnthropic(model='claude-3-7-sonnet-latest')
prompt = f"""
You are a customer service AI for a water utility company. Classify the following customer input into one of these categories:
{', '.join(CALL_TYPES)}
Customer input: "{customer_input}"
Respond with just the category name, nothing else.
"""
# Get the response from Claude
response = model.invoke(prompt)
predicted_type = response.content.strip()
return predicted_type透過僅將文字傳遞給大型語言模型(LLM),我們可以將現實世界的類知識與提取出來的、返回並進行比較的類知識隔離開來。
def compare(customer_input, actual_type)
predicted_type = classify(customer_input)
result = {
"id": call["id"],
"customer_input": customer_input,
"actual_type": actual_type,
"predicted_type": predicted_type,
"correct": actual_type == predicted_type
}
return result使用 Cloud 3.7 Sonnet(截至撰寫本文時的最新模型)在整個合成資料集上運行此模型,效能非常高,91% 的通話都被準確分類:
"metrics": {
"overall_accuracy": 0.91,
"correct": 91,
"total": 100
}如果這些是真實的電話,而我們事先不知道電話的類別,我們仍然需要審查所有 100 個電話,才能找出 9 個被錯誤分類的電話。
透過應用上述強大的決策電路,我們獲得了類似的準確率結果。 相信 在這些答案中。在這種情況下,整體準確率為 87%,但在我們高置信度答案中,準確率高達 92.5%。
{
"metrics": {
"overall_accuracy": 0.87,
"correct": 87,
"total": 100
},
"confidence_metrics": {
"high": {
"count": 80,
"correct": 74,
"accuracy": 0.925
},
"medium": {
"count": 18,
"correct": 13,
"accuracy": 0.722
},
"low": {
"count": 2,
"correct": 0,
"accuracy": 0.0
}
}
}我們需要確保所有答案都百分之百準確,因此還有很多工作要做。這種方法讓我們能夠更深入地探究… 原因 高置信度響應的不準確度。在這種情況下,較弱的聲明和簡單的驗證能力無法捕捉到所有問題,從而導致分類錯誤。這些能力可以不斷改進,以期在高置信度響應中實現 100% 的準確率。
改進過濾系統,以提高結果的可靠性。
目前的系統將主要分析師和儲備分析師意見一致的回應歸類為「高置信度」。為了提高準確性,我們需要對「高置信度」的定義更加嚴格。
# Modified high confidence logic
if (primary_result['call_type'] == backup_result['call_type'] and
primary_result['call_type'] is not None and
validation_result and
negative_check == 'yes' and
additional_validation_metrics > threshold):
return {'call_type': primary_result['call_type'], "confidence": "high"}透過增加更多篩選標準,我們將獲得數量較少的「高置信度」結果,但這些結果會更加準確。這項對篩選系統的改進旨在減少誤差,並提高被歸類為高品質數據的可靠性。
其他驗證技術:提高分析的準確性
以下是一些改進資料驗證和分析流程的其他建議:
三級分析儀增加第三種獨立的分析方法。這種方法起到額外的驗證作用,將兩種不同分析方法的結果與第三種方法的結果進行比較,以確保更高的準確性並降低出錯的可能性。
# Only mark high confidence if all three agree
if primary_result['call_type'] == backup_result['call_type'] == tertiary_result['call_type']:歷史模式匹配將結果與歷史準確結果(例如病媒研究)進行比較。這種方法使用可靠的歷史數據作為參考,並將當前結果與之對比,以識別任何偏差或不一致之處。它可以被視為一種分析“記憶”,有助於發現異常情況或意外發現。
if similarity_to_known_correct_cases(primary_result) > 0.95:對抗性測試對輸入資料進行微小調整,並檢查分類結果是否保持穩定。此方法旨在透過對資料進行微小變化來測試分類系統的穩健性。如果系統對這些變化高度敏感,則可能表示系統有缺陷或潛在偏差。
variations = generate_input_variations(customer_input)
if all(analyze_call_type(var) == primary_result['call_type'] for var in variations):
LLM提取系統中人為幹預的一般公式
- N = 總執行次數(本例為 10,000)
- p_1 = 基本語言分析器準確度(在本例中為 0.8)
- p_2 = 備用語言分析器的準確率(在本例中為 0.8)
- v = 模式驗證器有效性(本例為 0.7)
- n = 負面檢查者有效性(本例為 0.6)
- H = 所需人工介入次數
- E_final = 最終未偵測到的錯誤
- m = 獨立審計師人數
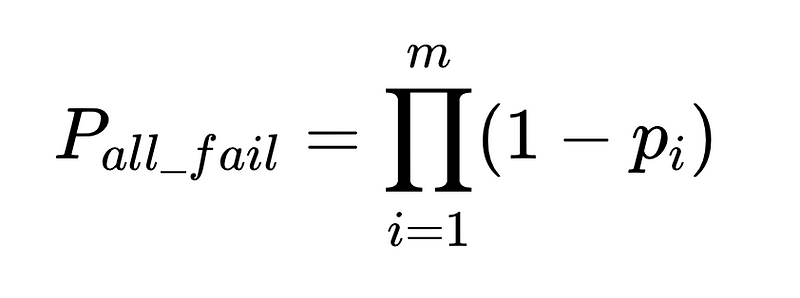
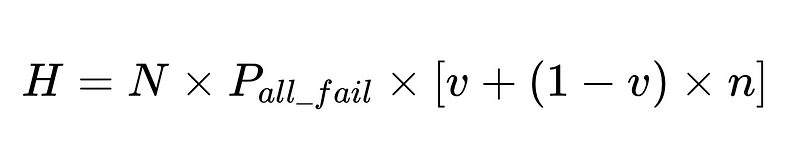
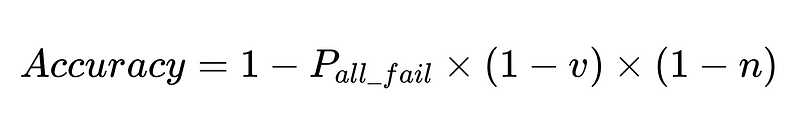
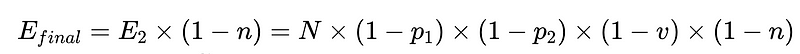
最優系統設計
該方程式揭示了自然語言處理(NLP)系統準確性的關鍵資訊:
- 添加解析器會降低產量,但會提高整體準確率。
- 此系統的精度受以下因素限制:
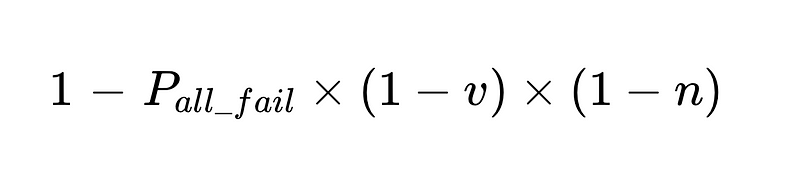
- 人為介入是適度的 直接的 總共執行了 N 次。
例如:
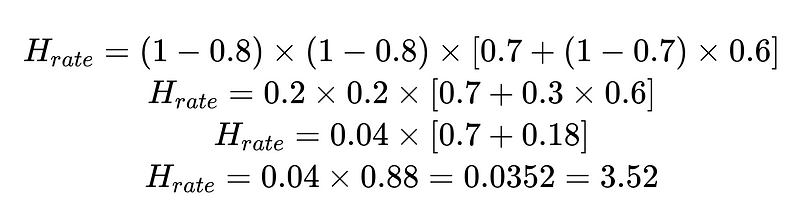
我們可以使用計算出的人工幹預率 (H_rate) 來即時追蹤解決方案的有效性。如果人工幹預率開始上升到 3.5% 以上,則表示系統故障。如果人工幹預率持續低於 3.5%,則表示我們的改進措施正在按預期發揮作用。
成本函數
我們還可以創建成本函數來幫助我們改進系統。成本函數是一種強大的分析工具,可用於評估系統的財務績效並識別潛在的改進領域。
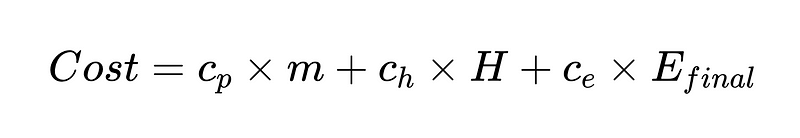
在哪裡:
- c_p = 每個語法分析器的營運成本(在本例中為 0.10 美元)
- m = 語法分析器執行的次數(在本例中為 2 * N)
- H = 需要人工介入的病例數(在本例中為 352)
- c_h = 一次人工幹預的成本(例如 200 美元:4 小時,每小時 50 美元)
- c_e = 每次未偵測到的錯誤的成本(例如,1000 美元)
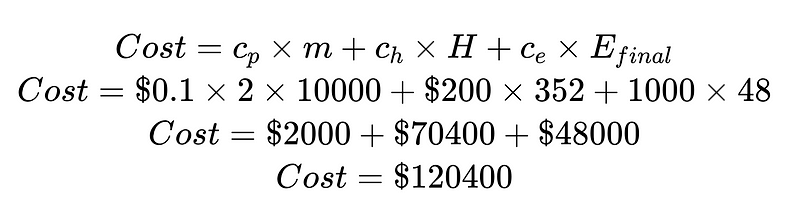
透過將成本分解為人工幹預成本和未檢出錯誤成本,我們可以優化系統整體。在本例中,如果人工幹預成本(70,400 美元)過高且不可承受,我們可以專注於提高高置信度輸出。如果未檢出錯誤成本(48,000 美元)同樣過高且不可承受,我們可以引入 Plus 語法解析器來降低未檢出錯誤率。
當然,成本函數最有用的用途是探索如何改善它們所描述的情況。
根據上述場景,為了將未偵測到的錯誤數量 E_final 減少 50%,其中
- p1 和 p2 = 0.8,
- v = 0.7 和
- N = 0.6時
我們有三種選擇:
- 新增一個準確率 50% 的語法分析器,並將其作為輔助分析器。值得注意的是,這樣做會帶來一些權衡:運行 Plus 語法分析器的成本會隨著人工幹預成本的增加而增加。
- 將現有語法分析器的效能分別提高 10%。考慮到這些語法分析器所執行任務的難度,這或許能夠實現,也或許不能實現。
- 審計流程改進了15%。但這同樣因為人為介入而增加了成本。
人工智慧可靠性的未來:透過精準定位建立信任
隨著人工智慧系統日益融入商業和社會的關鍵領域,追求近乎完美的精準度將變得至關重要,尤其是在敏感應用領域。透過採用受電路啟發的人工智慧決策方法,我們不僅可以建構高效擴展的系統,還能憑藉始終如一的可靠性能贏得用戶的深切信任。未來不在於最強大的單一模型,而是精心設計的系統,這些系統能夠將多方視角與策略性的人工監督結合。
正如數位電子產品從不可靠的組件發展成為我們信賴並能承載最關鍵數據的電腦一樣,人工智慧系統如今也正經歷著類似的演進歷程。本文所述的框架代表了最終將成為關鍵任務型人工智慧標準架構的初始藍圖——這些系統不僅承諾可靠性,而且在數學上也保證了可靠性。如今的問題不再是我們能否建構出近乎完美的人工智慧系統,而是我們能以多快的速度將這些原則應用到我們最關鍵的應用程式中。
評論被關閉。