

抽象的:
- 微軟推出了 Phi-4 推理 AI 模型,分別使用 14 億和 3.8 億個參數進行訓練。
- 儘管 Phi-4 推理模型體積小巧,但其性能足以媲美 DeepSeek R1 和 o3-mini 等體積更大的模型。
- 微軟表示,由於 Phi-4 推理模型體積小,因此可以在 Windows Copilot+ 電腦上執行。
微軟發布了三款全新的推理人工智慧模型:Phi-4-reasoning、Phi-4-reasoning-plus 和 Phi-4-mini-reasoning。這些小型語言模型專為 Windows PC 和行動裝置等周邊設備而設計。其中,Phi-4-reasoning 人工智慧模型已使用 14 億個參數進行訓練,能夠執行複雜的推理任務。

Phi-4-reasoning-plus 模型採用相同的基本模型,但在推理時間計算中加入了「Plus」——其詞元數量約為 Phi-4-reasoning 的 1.5 倍——從而實現了更高的準確率。儘管規模較小,Phi-4-reasoning 模型仍能與規模更大的模型相媲美,例如: 深尋R1 671B 和 o3-mini。
在 GPQA 基準測試中,Phi-4-reasoning-plus-14B 模型在記錄過程中獲得了 69.3% 的分數。 o3-迷你 結果為 77.7%。然後在 AIME 2025 測試中,Phi-4-reasoning-plus-14B 的準確率為 78%,而 o3-mini 的準確率為 82.5%。這顯示微軟的迷你模型正在接近規模更大的主流推理模型。
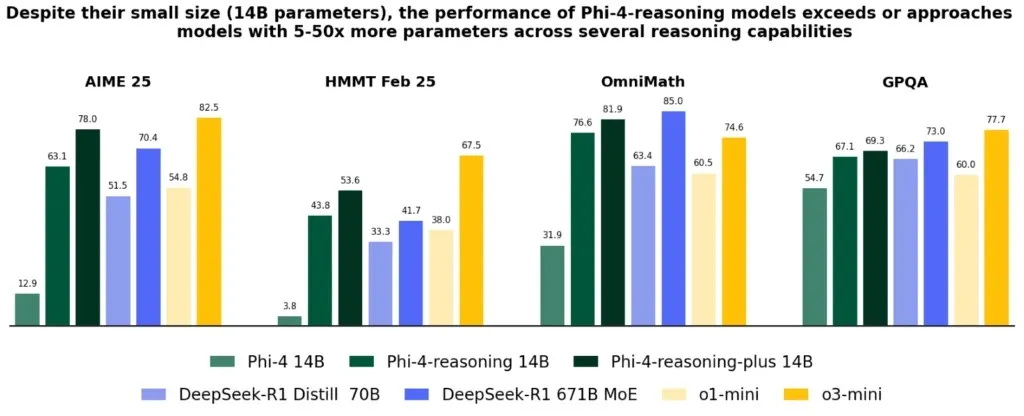
微軟表示,Phi-4 推理模型是透過監督式微調進行訓練的。基於 OpenAI o3-mini 精心策劃的推理演示此外,微軟寫道:「該模型表明,準確的資料格式和高品質的合成資料集可以讓較小的模型與較大的模型競爭。“
除此之外,僅使用 3.8 億個參數訓練的小型 Phi-4-mini-reasoning 模型,其性能優於許多 7 億和 8 億參數的模型。在 AIME 24、MATH 500 和 GPQA Diamond 等基準測試中,Phi-4-mini-reasoning-3.8B 模型取得了具有競爭力的結果,接近 o1-mini 模型的效能。調整Phi-4-mini 型號準確使用Deepseek-R1模型產生的合成數據“
微軟的 Phi 模型已經在 Windows 電腦上本機使用了。 副駕駛+電腦它採用了整合式神經處理單元。 Phi-4推理模型如何提升該設備的AI性能,值得我們拭目以待。
評論被關閉。