

人工智慧影像生成模型發展迅速,但它們產生品質參差不齊的影像仍然屢見不鮮。由於人們很容易認為問題出在人工提示上,所以我決定測試一下,如果只使用人工智慧產生的提示,其效率是否會更高。像 ChatGPT 和 Gemini 這樣的人工智慧影像生成工具,其結果很大程度上依賴於提示的品質和準確性。如果使用自動化提示,結果會有所不同嗎?這就是我們將在本實驗中探究的問題。
![]()
實驗規則
幾年前人工智慧影像生成模型剛出現時,我們都以為它們會為視覺媒體從業人員敲響警鐘。但事實並非如此。雖然它們可以產生極其逼真的圖像,但人工智慧圖像往往難以預測,尤其是在需要更複雜的圖像時(例如,人工智慧在生成手部圖像方面往往表現不佳)。
你可以把這個問題歸咎於人工智慧模型本身,也可以歸咎於人類的不足以及我們在撰寫聲明方面的技能參差不齊。檢驗責任歸屬的一個自然方法是,看看當你輸入生成的聲明時,圖像生成模型的表現是否會更好。

人工智慧(AI)能否為我們提供看待歷史事件的新視野?
為了驗證這個假設,我將使用 Gemini 產生一系列提示,這些提示會避免使用我想要建立的物件或映像的名稱。這將有助於驗證人工智慧對指令的「理解」程度。誠然,模型仍然有可能受到訓練資料的強烈影響(尤其是在重建現有圖像時),但正如年輕人所說,這就是現實。
我選擇使用 Bing(沒錯,Bing 仍然存在)影像建立器來建立影像,它基於 DALL-E 3。為了測試該模型,我將從簡單的形狀開始,然後隨著實驗的進行,逐步過渡到更複雜的圖像。
如果你用過 ChatGPT 或類似的工具,你肯定知道它們的一些回應有多麼不可靠,而我在「測試」過程中看到的表單提示也不例外。因此,我決定將字數限制在 500 個字元以內,以保持提示的一致性。
人工智慧如何處理簡單形狀?
我們先從一個簡單的正方形開始。我請 Gemini 描述一個正方形,但不要說出它的名字,以下是他的描述:
“一個四邊形,它的四條邊長度都相等。每個內角都是90度。它是一個正四邊形,對邊平行。”
將描述輸入DALL-E後,我得到了以下結果:
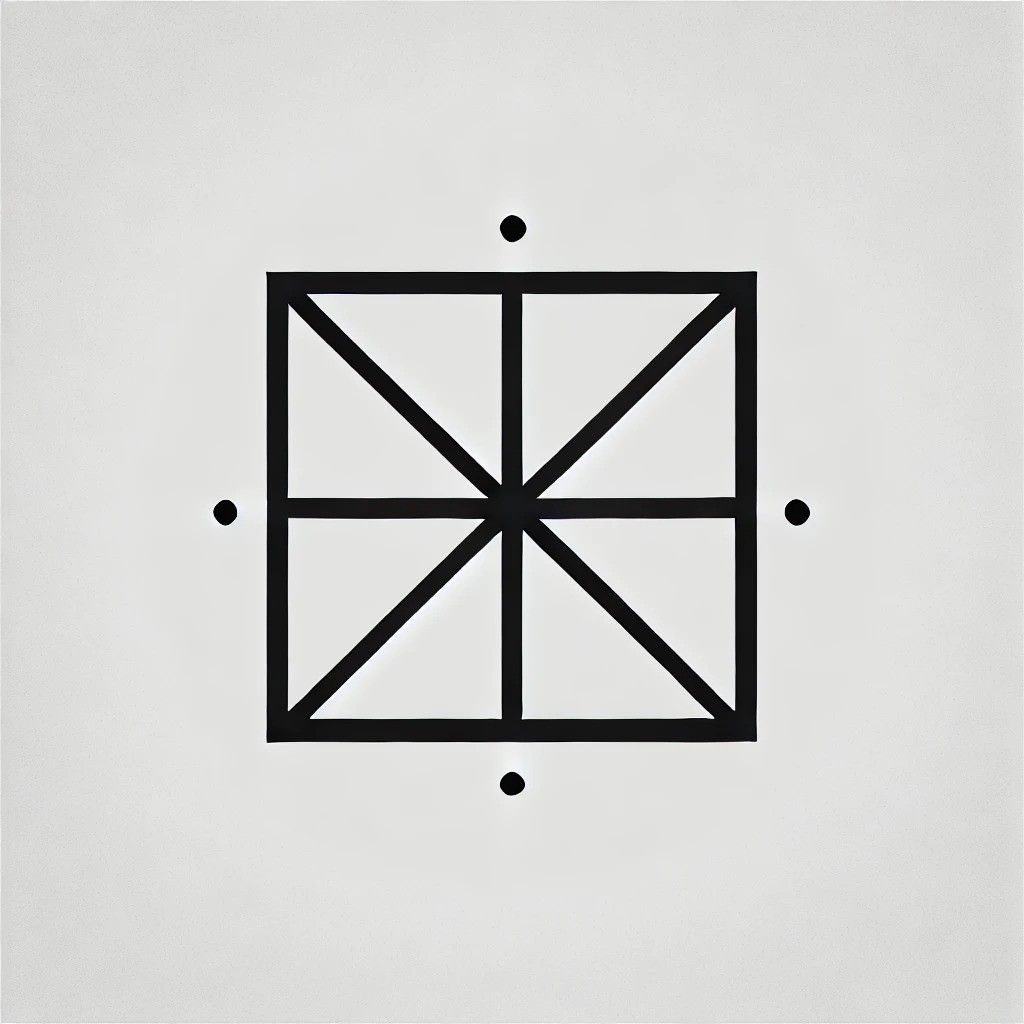
好吧,它是個正方形,雖然我覺得它有點太幾何化了。是時候增加難度了,所以我請AI畫一個立方體。
「一個具有六個相同面的三維圖形。每個面都是一個正四邊形,四條邊相等,四個角均為直角。它有12條長度相等的邊和8個頂點。圖形內的所有角均為直角。”
結果令人驚嘆:

還記得我們之前說的人工智慧模型的不可預測性嗎?嗯,在這裡,DALL-E 創建了一個立方體,但卻有點搞混了,把它變成了魔術方塊。雖然它完全避開了「魔術方塊」這個詞,但人工智慧確實犯了一個部分錯誤——我們可以將這歸因於匈牙利益智遊戲魔術方塊的流行。
人工智慧視角下的人物攝影
這個立方體的姿態表明,即使有了精確且「客觀」的描述,人工智慧仍然可能誤解簡單的指令。因此,讓我們看看它在處理人工智慧生成的經典圖像描述方面表現如何,例如多蘿西婭·蘭格的《移民母親》。以下是原圖:

照片中,一位女子麵露憂色,目光躲閃著,看向別處。她的孩子們圍在她身邊,有的躲在角落,有的背對著鏡頭。她一隻手放在臉旁,流露出疲憊和痛苦。畫面暗示著貧困和艱辛。女子衣衫襤褸,整體構圖陰鬱,更凸顯了她所處的困境。
這是DALL-E對這幅著名照片的詮釋:

非常接近!但並不完全準確,因為DALL-E顯然省略了“她被孩子們包圍著,孩子們都躲在後面或轉過臉去。影片中,不是「母親」把手放在臉旁,而是其中一個孩子扮演了這個角色。
讓我們來嘗試一些更複雜的問題。你可能看過那張著名的照片「摩天大樓頂上的午餐」:

「11名男子坐在高高的鋼樑上吃午飯,雙腿懸空。鋼樑懸掛在一座綿延的城市上方。儘管身處極高的高度,這些男子卻顯得很放鬆。他們穿著工作服,而且拍攝角度略低,更突顯了高度感。”
這絕妙的主張帶來了絕妙的結果:

一旦你忽略了人工智慧生成圖像的經典特徵(相同的鍋碗瓢盆、複製的主題),這張圖的構圖和整體感覺就幾乎令人驚訝了。不過,這其實並不奇怪——這張圖不僅極為常見,而且還屬於公共領域,所以我隱隱懷疑DALL-E實際上是在訓練過程中重建了它的內容。
人工智慧能否處理複雜影像?
既然這是實驗的最終“測試”,那就得認真起來了!雖然人工智慧擅長處理人類影像,但在面對複雜且模糊的場景時,它往往會束手無策。那麼,阿波羅8號從月球軌道拍攝的著名「地球升起」照片又該如何處理呢?

「一個部分發光的球體懸掛在黑暗的空間中。一個較小的灰色球體從它的地平線上升起。較大的球體上呈現出藍色和白色的斑塊,分別代表水和雲。兩個球體與黑暗環境的鮮明對比,突顯了較小上升球體的脆弱和孤立。」
雙子座(或更確切地說,是那個球體)無法勝任這項描述。鑑於其高度抽象性,我在描述中添加了“從附近的月球軌道拍攝”的字樣,但這並沒有什麼幫助:

這是一張華麗而精緻的搖滾專輯封面,但它與《地球升起》毫無關係。為了完善這個實驗,我選擇了迄今為止最神秘的圖像——愛德華·韋斯頓的工業傑作《阿美鋼鐵》:

畫面中佈滿了圓形的工業金屬罐。它們造型光滑飽滿,形成重複的圖案。光線在罐體表面反射,凸顯它們的曲線,營造出立體感。構圖著重展現工業物品的抽象特質,強調形式與質感而非功能。畫面簡潔現代,光影效果運用得恰到好處。
這似乎是一個不錯的切入點;讓我們看看達爾-E是否同意我們的看法:

雖然我很欣賞其中的科幻元素,但這和原圖一點都不像。我不想讓實驗以災難性的方式結束,所以決定幫機器一把,在輸入內容的末尾加上「1920年代照片」這句話。
我當時的想法是,這個特定的字眼或許能幫助我更能理解我所指的圖像。可惜的是,Dall-E 又一次讓我失望了,他創作的又是一張前衛搖滾專輯封面:

這項實驗的結果很有意思,我們可以得出的結論是,人工智慧產生的圖像具有高度不可預測性,尤其是在處理更抽象的概念時。無論輸入的是人工智慧產生的準確影像,還是人類生成的不完美影像,結果都顯得隨機。
所以,下次當你試圖責怪自己和你的輸入方式時,請記住,即使兩個設備相互通信,結果也可能非常相似。
評論被關閉。