

自從它出現以來 雙子座3 他首次成功保住了自己在榜首的位置。 LMArena排行榜該榜單是一個綜合排名,由數千名真實用戶對不同型號進行比較得出。 人工智能 它們在各種任務上進行正面較量,並投票選出最佳答案。但說到達到最嚴苛的推理標準,一顆冉冉升起的新星出現了,它已經超越了谷歌——而且它並沒有訓練自己的模型。
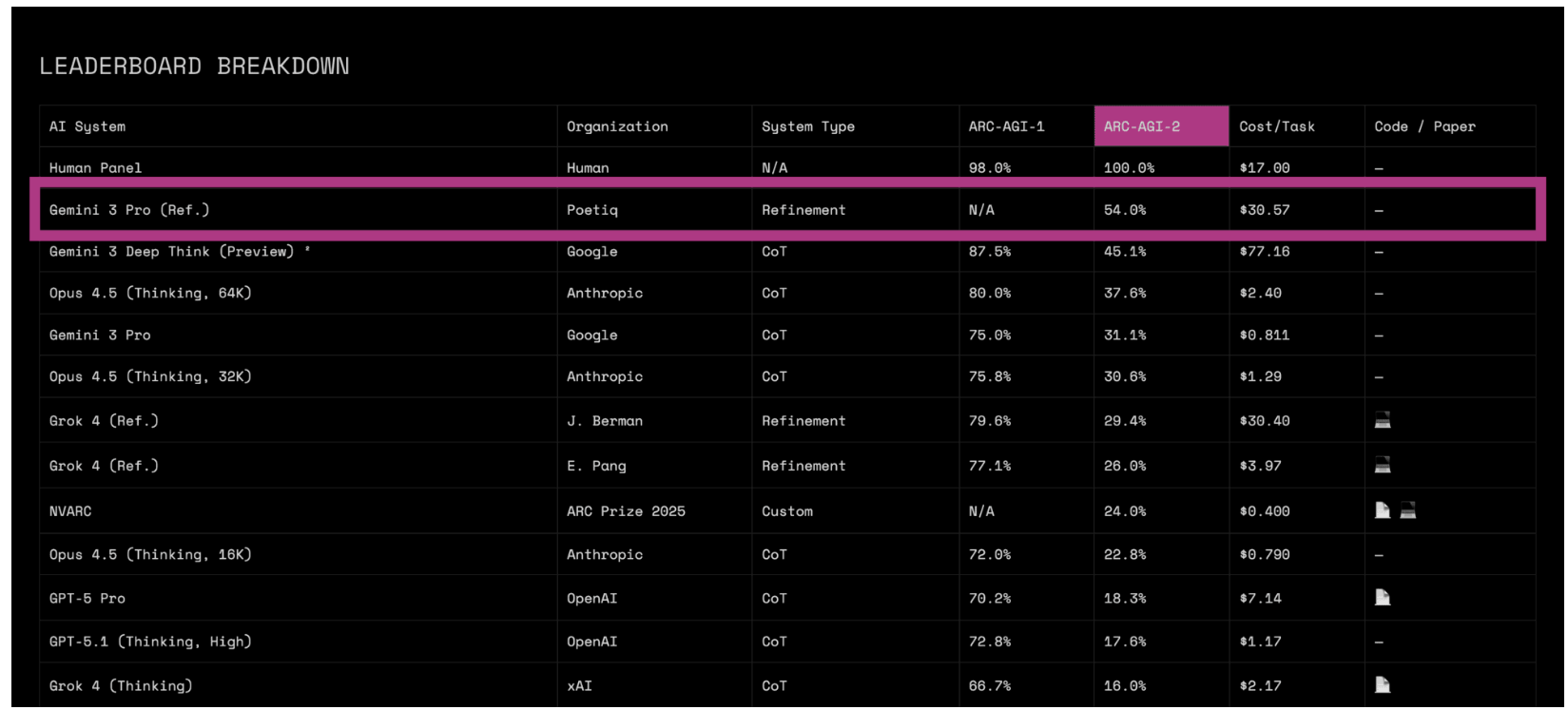
一家名為 Poetiq 的六人創業公司聲稱其排名第一 ARC-AGI-2 半特殊測試套件這是人工智慧研究員 François Chollet設計的一項難度極高的推理挑戰。這家新創公司的系統得分54%,超過了Google先前公佈的Gemini 3 Deep Think系統約45%的得分。

換個角度來看,就在六個月前,大多數人工智慧模型在這個基準測試中的準確率還不到5%。研究人員普遍認為,突破50%的準確率需要數年時間。
最令人驚訝的是:Poetiq 的突破並非源自於一種全新的前沿模式,而是源自於更巧妙地組織現有模式的方式。
Poetiq是如何實現這項壯舉的?
Poetiq並沒有從零開始建立一個龐大的轉換器,而是開發了一種名為「元系統」的機制;本質上,它是一個人工智慧控制器,可以監控、評估和改進任何連接到它的模型的輸出。在他們的ARC-AGI-2專案中,團隊使用了Gemini 3 Pro作為基礎模型。
Poetiq 將該系統描述為一個嚴格控制的最佳化循環: 創建 > 批評 > 改進 > 檢查。
它之所以特別,是因為它:
- 無需再培訓: 該系統可在數小時內適應新模型。
- 它完全基於大型的、現成的語言模型: 暫無自訂編輯功能
- 降低成本: 據報道,Google的 Deep Think 每次任務收費 77 美元;Poetiq 的系統收費接近 30 美元。
- 開源: 該解決方案已公開,且可驗證。
- 自我審計: 系統會先評估自身的答案,然後再回到最終結果。
على 網站 Poetiq 團隊表示,對於該公司而言,這種方法的原理是利用現有大型語言模型的推理能力來提取 Plus,而不是透過蠻力擴展計算能力。
為什麼 ARC-AGI-2 測試很重要?

雖然大多數標準化測驗衡量的是程式設計或數學等有限的技能,但 ARC-AGI-2 的設計目的是測試更深層的東西:模式識別、測量、抽象推理以及人類在幼兒時期學習到的那種概括能力。
它故意設定得非常困難,而且對現有的大型語言模型(LLM)極為不友善。即使是許多複雜的模型,在這種環境下也會慘敗。
因此,半年內成功率從個位數躍升至54%令人驚訝。這表明推理方法取得了進步,而不僅僅是原始模型規模的擴大。
然而,Poetiq 的測試結果僅適用於半私有的測試組,並未完全對外開放。該公司網站稱,該結果已由基準測試機構驗證,但獨立的第三方復現測試仍在進行中,這對於此類影響的基準測試至關重要。
下一個突破可能並非來自更大的模型,Poetiq 的工作凸顯了人工智慧領域一個日益增長的趨勢:進步並不總是需要數十億美元的基礎設施或龐大的研究實驗室。
如果這類系統能夠超越標準參數,涵蓋規劃、程式設計、研究,甚至現實世界的決策,它們將重塑人工智慧的開發方式。企業或許不再需要等待下一代超級計算機,而是可以專注於建構複合智能,使現有模型更智能、更經濟、更穩定。
結論
Poetiq 發布了 ARC-AGI 的開源解決方案,以便研究人員可以測試、擴展甚至質疑其結果。該標準包含一個隱藏的測試集,歷史經驗表明,一旦大量人員進行獨立評估,結果可能會改變。
如果 Poetiq 的數據最終得以證實,這可能代表著人工智慧推理研究的一個轉折點。一個只有六人的團隊或許已經證明,模型組織可以媲美甚至超越訓練規模更大的模型。 Poetiq 剛剛證明,你不需要龐大的實驗室也能取得成功。
評論被關閉。