

現代Transformer視覺模型透過引入雜訊來提升2D和3D目標偵測的效能。本文將探討此機制的工作原理,並討論其對提升目標偵測模型精確度的貢獻,並著重於訓練過程中去雜訊技術的應用。

早期視覺的變形模型
DETR(偵測Transformer,Carion、Massa等人,2020)是最早用於目標偵測的Transformer架構之一,它使用學習到的解碼器查詢從影像編碼中提取偵測資訊。這些查詢是隨機初始化的,並且該架構沒有施加任何約束,使其學習類似錨框的目標。雖然它取得了與Faster-RCNN類似的結果,但其缺點是收斂速度慢-需要500個epoch才能完成訓練(DN-DETR,Li等人,2024)。較新的基於DETR的架構採用了可變形聚類,使得查詢能夠僅關注圖像的特定區域(Zhu等人,《可變形DETR:用於端到端目標檢測的可變形Transformer》,2020),而其他架構(Liu等人,《DAB-DETR:動態錨框是DETR的更佳查詢》,2022)則使用了空間錨框(使用k均值聚類生成,類似於基於錨框的CNN),這些錨框被編碼在初始查詢中。跳躍連接強制Transformer解碼器模組從錨框中學習回歸值來識別目標框。可變形注意力層使用預先編碼的錨框從影像中取樣空間特徵,並用這些特徵建立注意力標記。在訓練過程中,模型學習要使用的最佳錨框。這種方法教會模型在其查詢中明確地使用諸如目標框大小之類的特徵。
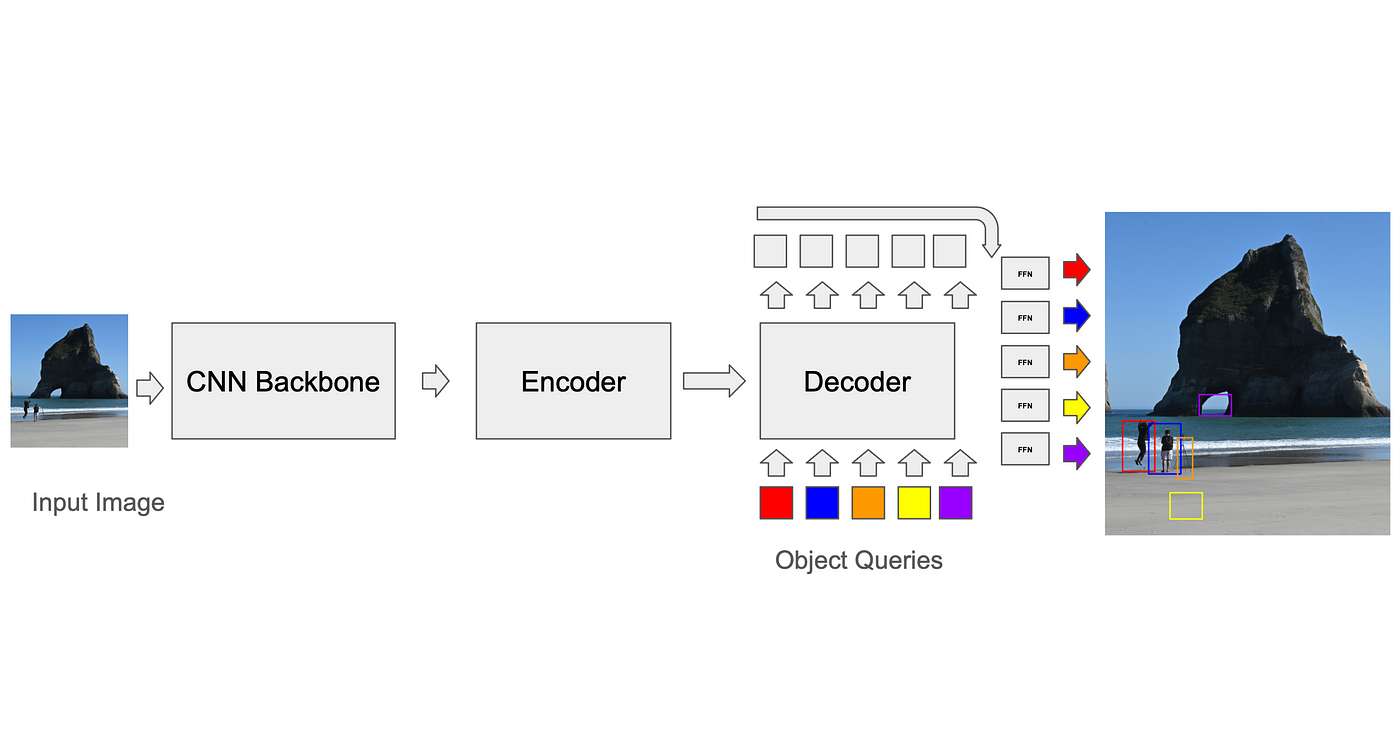
將預測結果與實際事實進行匹配:二元匹配演算法
為了計算損失,訓練器首先需要將模型的預測結果與基準(GT)方塊進行配對。雖然基於錨框的捲積神經網路(CNN)在解決這個問題上相對容易(例如,每個錨框在訓練期間只能匹配其自身體素內的GT框,並且在推理過程中使用非極大值抑制來消除重疊匹配),但由DETR開發的Transformer模型的標準做法是使用一種稱為匈牙利演算法的二元演算法。在每次迭代中,演算法會找到預測結果與基準事實之間的最佳匹配(即最佳化成本函數的匹配,例如所有框角點之間的平均平方距離總和)。然後計算預測框與基準事實框對之間的損失,並進行反向傳播。覆蓋預測(未與GT匹配的預測)會產生單獨的損失,這促使它們降低置信度。此過程對於提高模型準確率和減少誤差至關重要。
問題
匈牙利演算法的時間複雜度為 o(n³)。有趣的是,這並非訓練品質的瓶頸所在:Fenoaltea 等人於 2021 年發表的論文《穩定婚姻問題:物理學家視角下的跨學科綜述》指出,該演算法不穩定,這意味著其目標函數的微小變化會導致匹配結果的巨大變化,從而造成查詢訓練目標不一致。對於 Transformer 模型訓練而言,實際影響在於物件查詢可能在不同物件之間跳躍,並且需要很長時間才能學習到收斂的最佳特徵。換句話說,演算法的不穩定性會導致訓練過程波動,需要更多時間才能達到最優結果。
DN-DETR(基於雜訊抑制的目標偵測)
Li 等人提出了一種解決不穩定匹配問題的優雅方案,隨後被許多其他工作所採用,包括 DINO、Mask DINO、Group DETR 等。
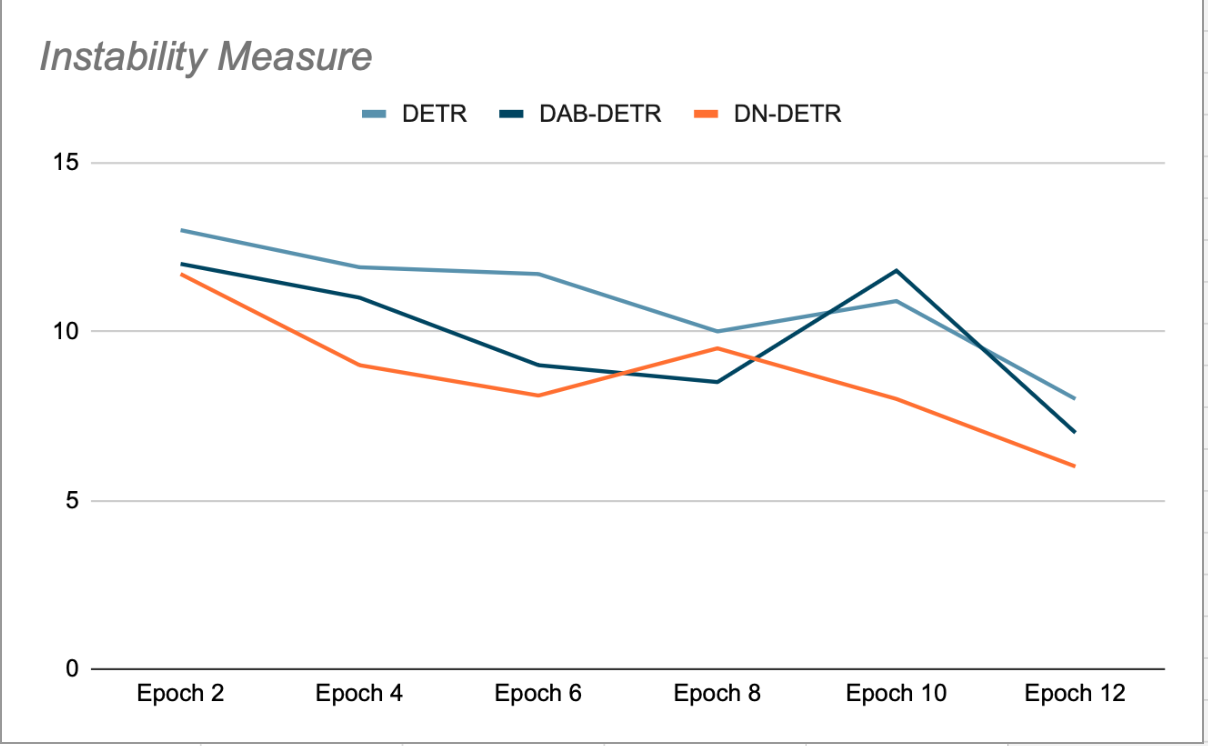
DN-DETR的核心理念是透過創造以下資源來加強訓練: 容易傾斜的假樞軸點匹配過程被繞過。這是在訓練過程中實現的:向真實地面(GT)框添加少量噪聲,並將這些帶有噪聲的框作為錨框輸入到解碼器查詢中。 DN 查詢與原始查詢相互隱藏,以避免可能幹擾訓練的交叉注意力。這些查詢產生的檢測結果已與其來源 GT 框匹配,無需進行雙向匹配。 DN-DETR 的作者表明,在每個 epoch 結束時的驗證階段(此時噪聲去除功能關閉),與 DETR 和 DAB-DETR 相比,這種方法提高了模型的穩定性,這意味著 Plus 查詢在連續的 epoch 中與 GT 對象的匹配保持一致(見圖 2)。
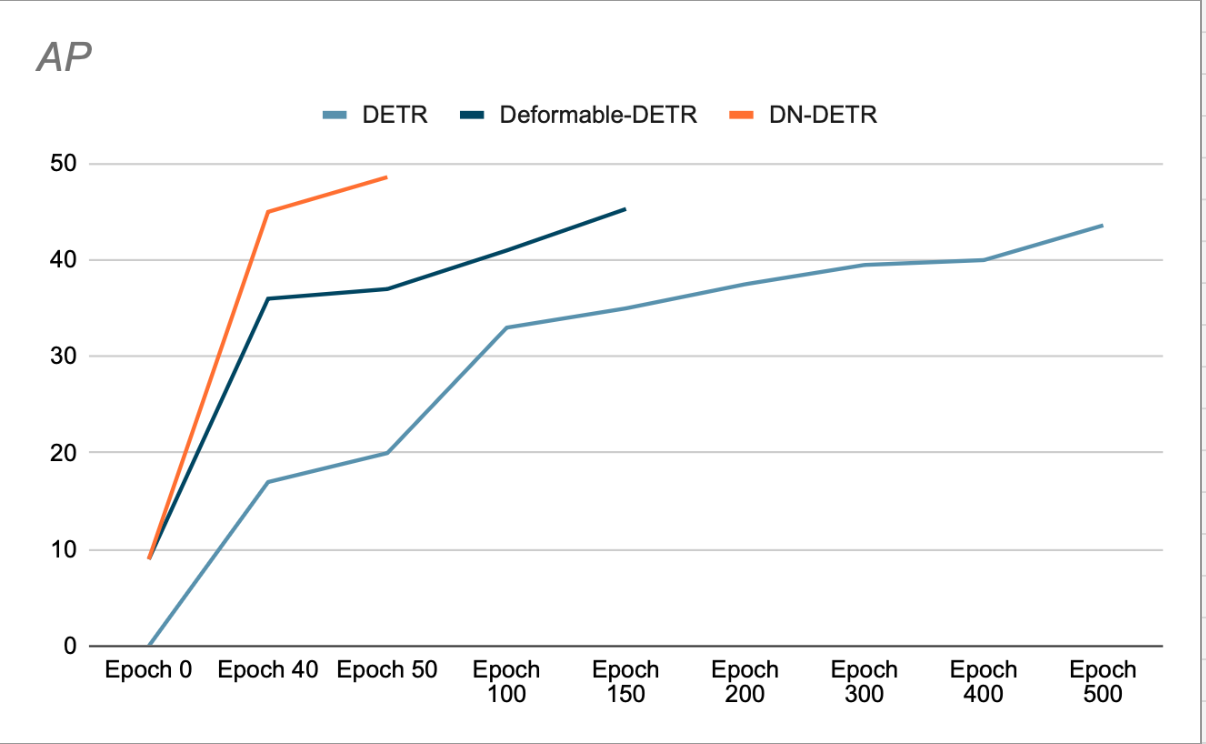
作者證明,使用 DN 可以加速收斂並獲得更好的檢測結果(見圖 3)。他們的移除研究表明,與先前的最佳方法(DAB-DETR,AP 42.2%)相比,使用 ResNet-50 作為骨幹網路時,在 COCO 檢測資料集上 AP(平均準確率)提高了 1.9%。
DINO 和對比雜訊消除
DINO進一步發展了這個理念,在降噪機制中加入了差分學習:除了正例之外,DINO還會為每個GT生成一個扭曲程度更高的版本,該版本通過數學方法生成,使其與GT的偏差比正例更大(見圖4)。這個版本被用作訓練的負例:模型學習接受最接近真實情況的發現,並拒絕偏差最大的發現(透過學習預測「無物件」類別)。
此外,DINO 還支援多種對比噪音消除 (CDN) 組合——每個 GT 物件都有多個噪音錨點——從而最大限度地發揮每次訓練迭代的優勢。
DINO 的作者報告稱,使用 CDN 時,平均準確率 (AP) 為 49%(在 COCO val2017 上)。
現代時間模型(例如 Sparse4Dv3)需要逐幀追蹤對象,它們使用 CDN 並添加時間噪音消除集,其中一些成功的 DN 錨點(以及非 DN 學習到的錨點)被儲存起來,以便在後面的幀中使用,從而增強模型的物件追蹤效能。

辯論
噪音去除(DN)似乎可以提高視覺變換檢測器的收斂速度和整體性能。然而,在對上述各種方法的演變進行考察後,會引發以下問題:
- DN技術可以改進使用可學習錨框的模型。但是可學習錨框真的那麼重要嗎? DN技術也能改進使用不可學習錨框的模型嗎?
- DN 對訓練的主要貢獻在於透過繞過二分圖匹配來增強梯度下降過程的穩定性。然而,二分圖匹配的存在似乎主要是因為 Transformer 工作的標準做法是避免對查詢施加空間約束。因此,如果我們手動將查詢限制在圖像的特定位置並放棄二分圖匹配(或者使用簡化的二分圖匹配,即對每個圖像塊分別運行),DN 是否還能提升結果?
我未能找到對這些問題給出明確答案的文獻。我的假設是,使用不可學習穩定器(前提是穩定器不太稀疏)和空間約束查詢的模型,1)不需要二元匹配演算法;2)在訓練過程中不會從數位網路(DN)中獲益,因為穩定器是已知的,學習其他臨時穩定器的回歸並無益處。
如果穩定器是固定的但分散的,我可以理解為什麼使用瞬態穩定器可以更容易地從它們上面下降,並且可以為訓練過程提供一個熱身。
Anchor-DETR(Wand等人,2021)比較了可學習和不可學習穩定器的空間分佈以及相應模型的性能。我認為,可學習性對模型表現的提升並不顯著。值得注意的是,他們在兩種方法中都使用了匈牙利演算法,因此尚不清楚他們是否可以在不進行二元匹配的情況下仍然保持效能。
需要考慮的一點是,在推理過程中避免使用 NMS 可能有正當的理由,這鼓勵在訓練中使用匈牙利演算法。
降噪在哪些情況下真正重要?我認為——在 追踪在追蹤過程中,模型接收一個視訊串流,其目標不僅在於偵測連續影格中的多個物體,還在於保持每個偵測到的物體的唯一標識。利用視訊串流的順序特性,時間Transformer模型並非獨立處理每一幀,而是維護一個儲存先前偵測結果的程式庫。在訓練過程中,追蹤模型被鼓勵從先前的物體檢測結果(更準確地說,是從與先前物體檢測結果相關的固定點)進行回歸,而不是簡單地從最近的固定點進行回歸。由於先前的檢測結果不受任何固定點網路的限制,DN所鼓勵的這種靈活性可能是有益的。我非常期待未來有研究工作可以解決這些問題。
以上就是關於降噪及其對視覺變換器貢獻的全部!如果您喜歡我的文章,歡迎閱讀我其他關於深度學習和機器學習的文章。 電腦視覺!
評論被關閉。