

抽象的:
- 谷歌推出了一項使用全新實驗性 Gemini 2.0 Flash 模型的原生影像產生和編輯功能。
- AI Studio 現在免費提供此功能,您可以使用簡單的文字命令來產生和編輯一系列一致的圖像。
- 您可以刪除和添加元素、插入文字、為圖像著色、創建視覺故事等等。
一年多來,我們一直在人工智慧領域聽到「原生多媒體」這個詞,但直到現在,各公司才開始充分發揮其人工智慧模型的多媒體潛力。谷歌終於發布了其最新模型“Gemini 2.0 Flash Experimental”,該模型具備了… 影像生成和編輯能力是一項基本技能。嘿.
現在,你可能想知道,圖像生成有什麼意義?其實,像 ChatGPT 這樣的主流 AI 聊天機器人早就具備影像生成功能了。當我們在 ChatGPT 或 Gemini 上產生 AI 影像時,指令會被傳送到專門的基於擴散的模型,例如 Dall-E 3 或 Imagen 3。這些模型經過圖像訓練,專門用於圖像生成;它們是主 AI 模型的擴展,而不是其組成部分。
然而,諸如語言視覺模型之類的 雙子座 它原生支援多媒體功能,這意味著它可以原生理解、產生和修改文字和圖像。迄今為止,還沒有任何一家科技公司向用戶提供這項功能。 OpenAI 曾在 2024 年展示其 GPT-4 的原生影像生成功能,但最終也未能發布。
 借助原始圖像生成功能,您將獲得 更好的一致性 多模態模型是基於海量不同媒體資料集進行訓練。因此,這些模型展現出對概念更深刻的理解和更廣泛的世界認知。
借助原始圖像生成功能,您將獲得 更好的一致性 多模態模型是基於海量不同媒體資料集進行訓練。因此,這些模型展現出對概念更深刻的理解和更廣泛的世界認知。
除了生成圖像外,您還可以使用簡單的文字命令無縫編輯圖像。例如,您可以上傳一張圖片,並指示模型添加太陽眼鏡、插入純文字、移除元素以及添加“+”號。與每次執行新指令都會重新產生整張影像的傳播模型不同,原生多媒體模型能夠在多次編輯後保持影像的一致性。
使用 Gemini 2.0 Flash 演示建立影像
目前,原始圖像創建功能不對普通用戶開放。具備原始影像建立功能的 Gemini 2.0 Flash 測試版僅在 Google 的 AI Studio 平台上提供。訪問免費。
在 AI Studio 上預覽模型後,不久的將來,它將在 Gemini 上發布,供所有人使用。不過,我試用了 Gemini 的新模型及其圖像創建功能,體驗非常棒。
首先,我製作了一個視覺化指南,以展示 Gemini 出色的影像生成能力。我讓 Gemini 製作一個關於如何製作煎蛋捲的視覺化指南,並為製作過程的每個步驟產生一張圖片。
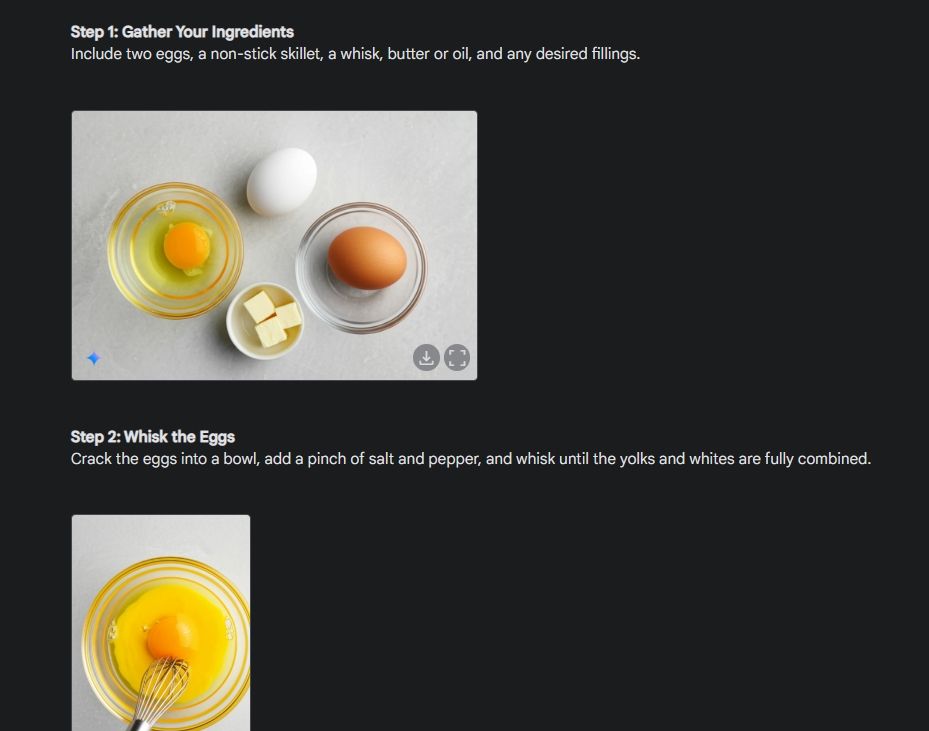
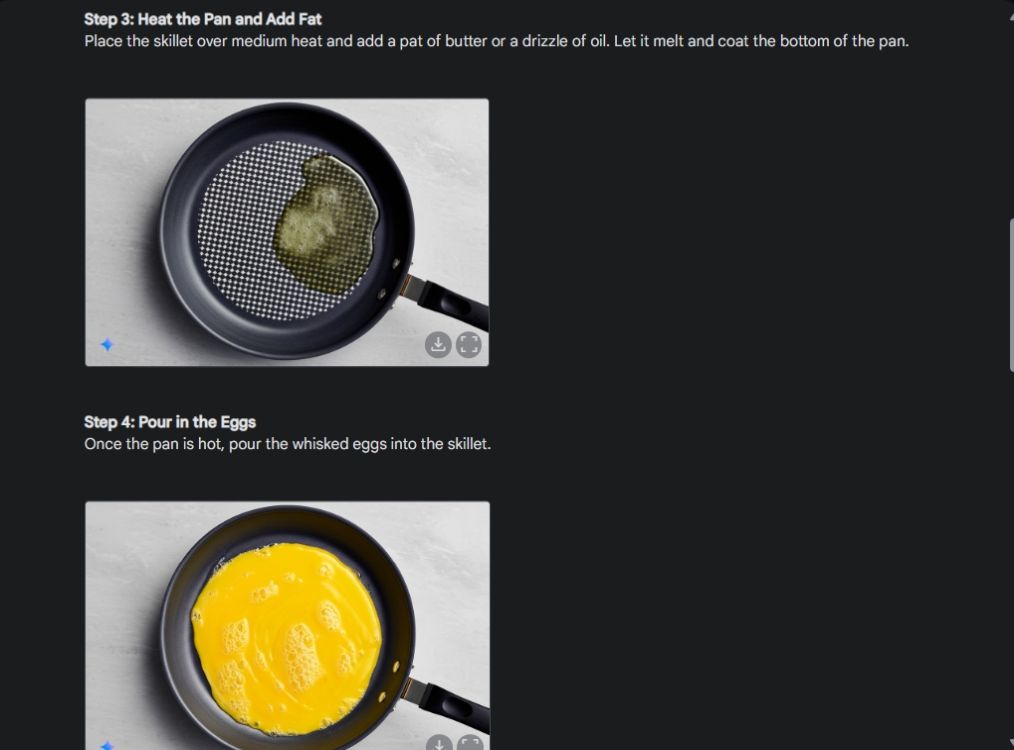

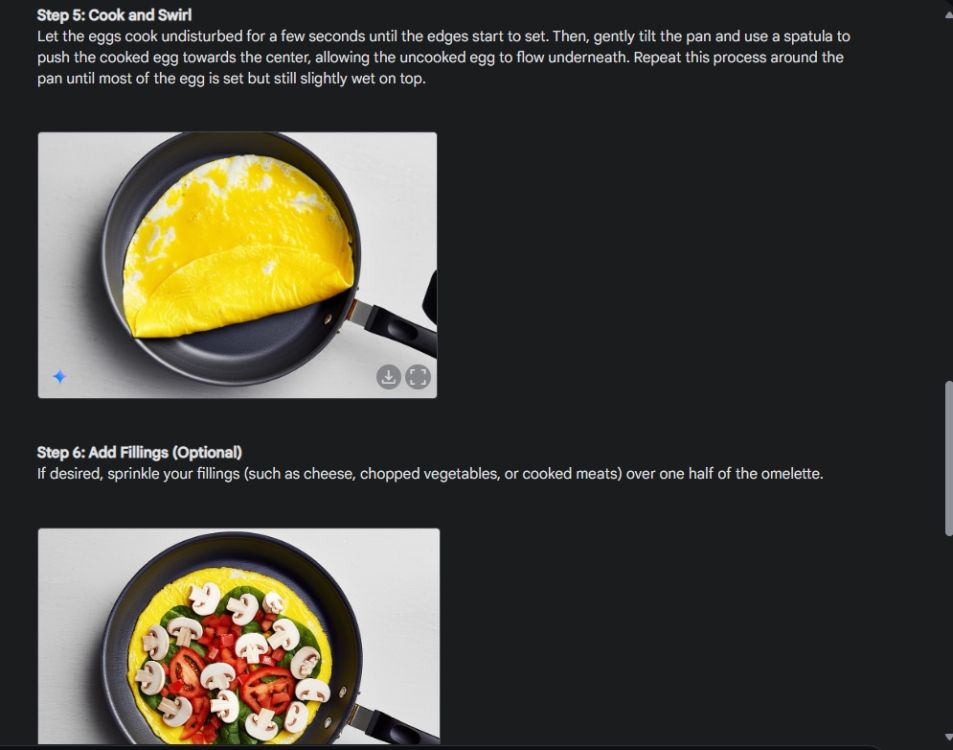
如您所見,所有圖像的結果都非常一致,沒有任何錯誤。甚至第二張圖的碗也完全相同。最後,您可以下載 1024 x 680 解析度的圖像。這樣,您就可以建立任何您想要的視覺指南。
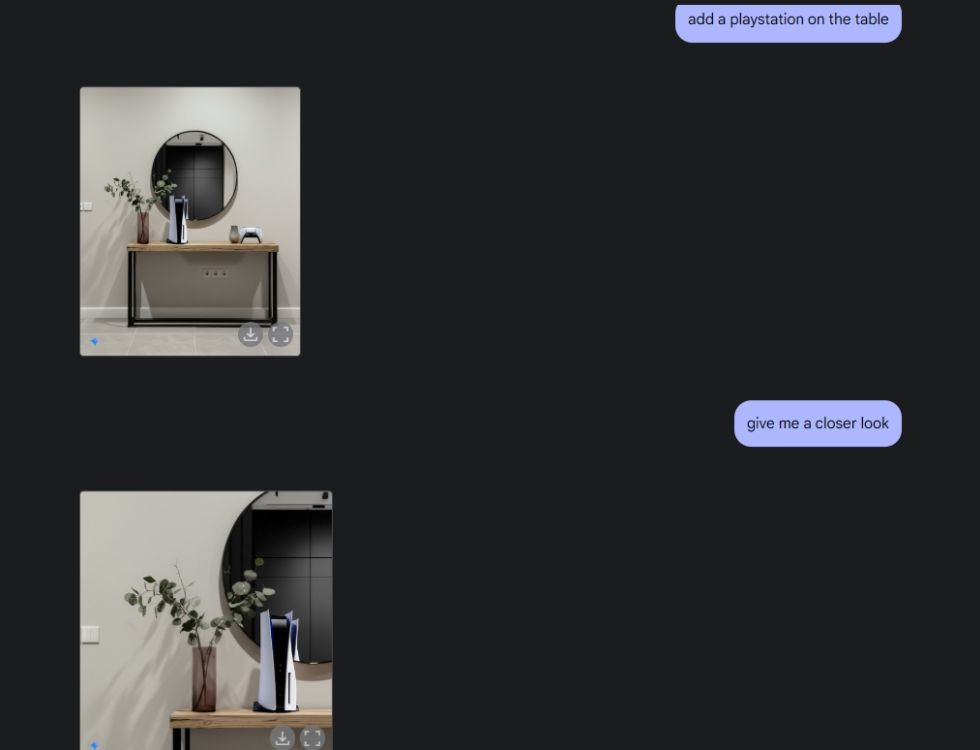
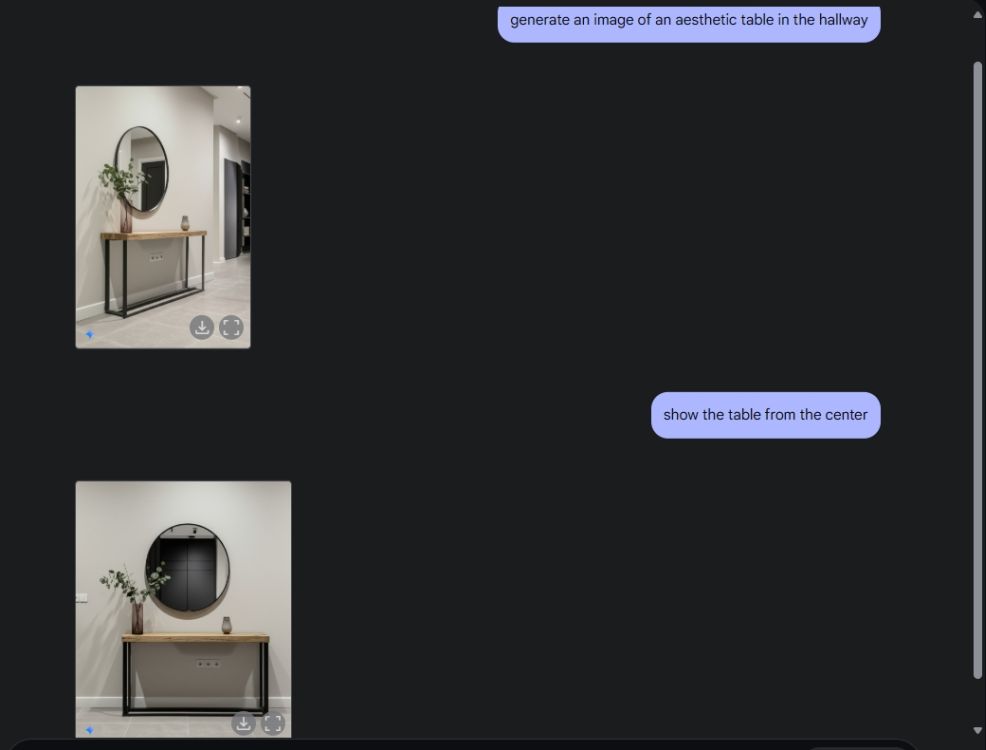
接下來,我請Gemini產生一張美觀的桌子影像,然後讓它從中心視角觀察這張桌子。它完美地完成了任務。之後,我又請Gemini在桌上增加一台PlayStation,並進行近距離觀察。 Gemini再次出色地完成了這項任務。正如您在下方看到的,人工智慧模型甚至將PS5在它身後鏡子中的倒影也還原了出來。
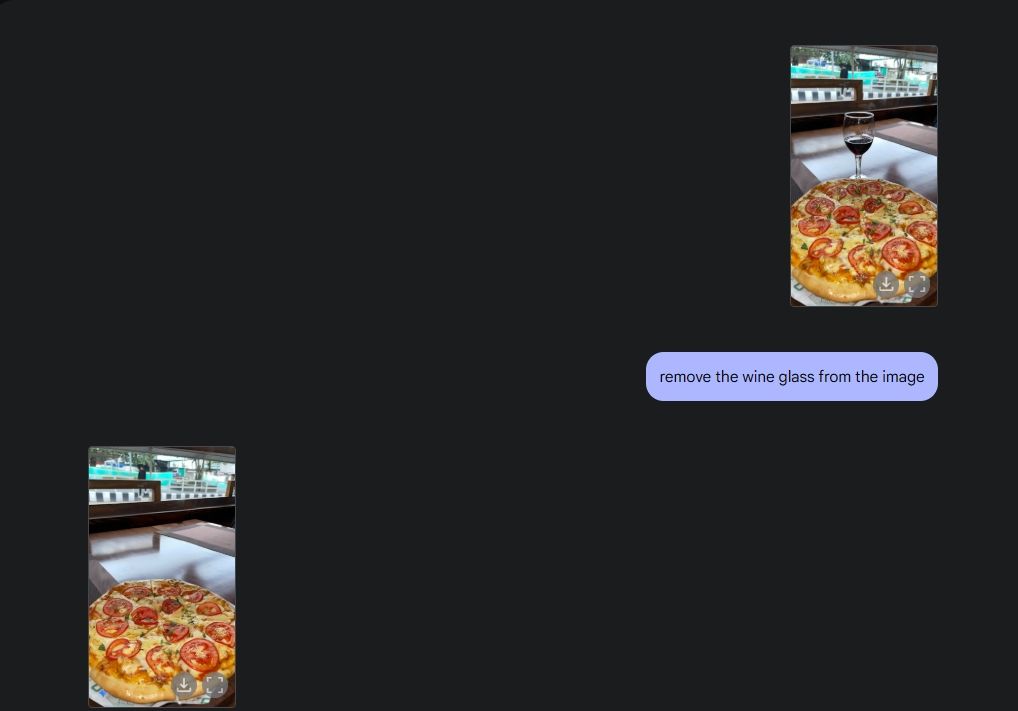
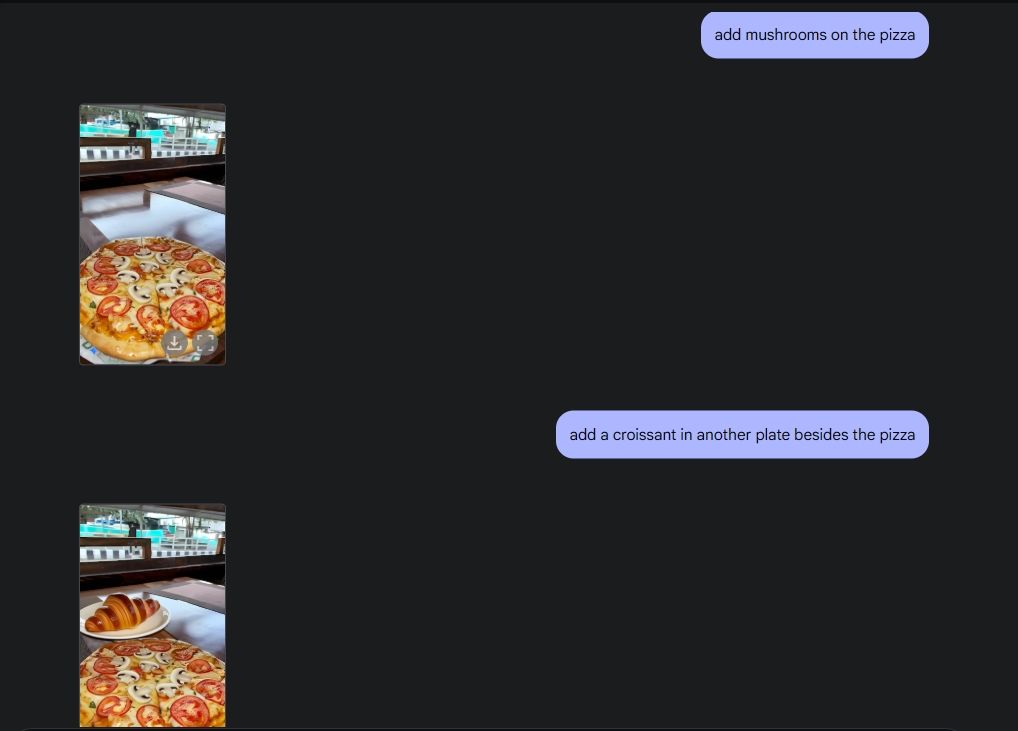
為了展示原始照片編輯功能,我從相簿上傳了一張照片,並請 Gemini 2.0 把桌上的酒杯去掉。接下來,我讓 Gemini 在披薩上加入蘑菇,它做得非常棒。然後我又讓 Gemini 添加了一個牛角麵包,瞧,這就是人工智慧照片編輯的全部魅力所在——這都要歸功於 Gemini 的多媒體功能。
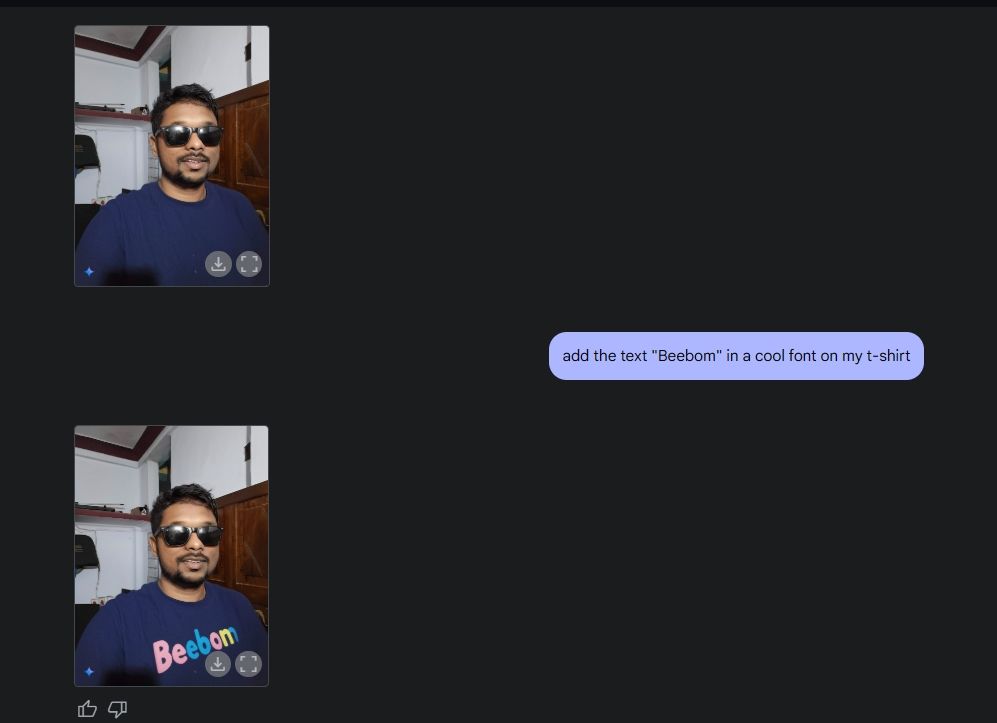
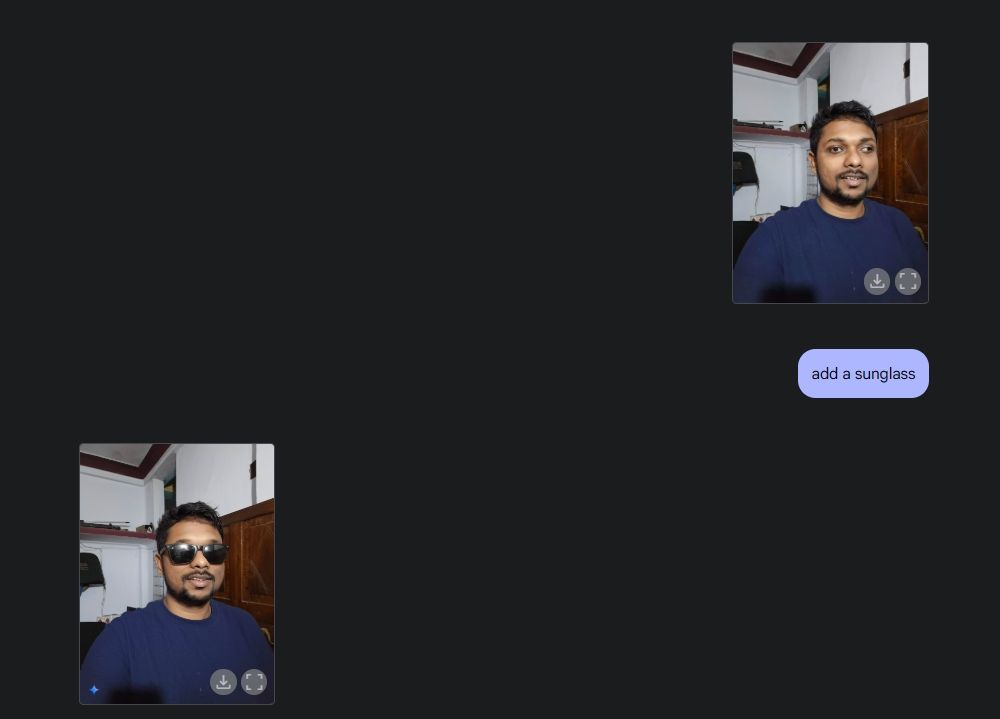
接下來,我上傳了一張自己的照片,請Gemini幫我加上太陽眼鏡,然後在我的襯衫上加上「Beebom」字樣。兩項都做得非常好。
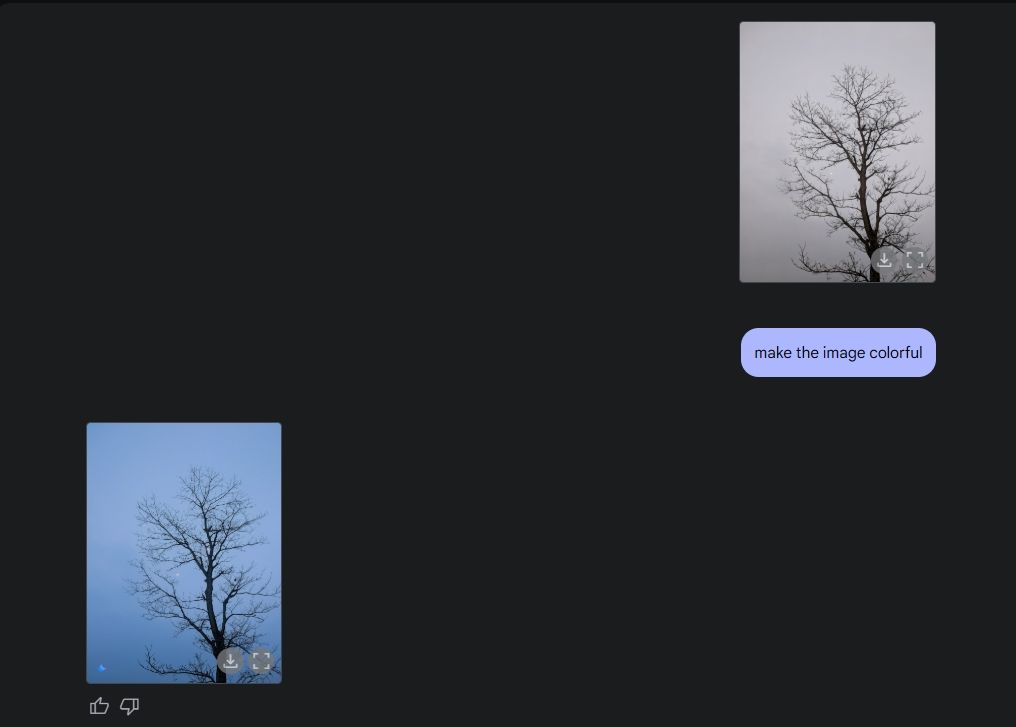
最後,我請Gemini幫我上色一張照片,他做得非常棒。我的意思是,照片看起來比以前好多了,沒有任何奇怪的錯誤、變形或缺少的部分。
Gemini 的全新多媒體功能有許多值得探索的應用場景。谷歌在原生圖像創建和編輯方面做得非常出色,我計劃在接下來的幾週內更廣泛地使用它,以測試其極限。
隨著用於影片創作的 Veo 2 和用於創建專業圖像的 Imagen 3 的發布,Google似乎在許多領域都超越了 OpenAI,而不僅僅是在人工智慧文字生成領域。因此,OpenAI 將如何憑藉 ChatGPT 重奪領先地位,值得我們拭目以待。
評論被關閉。