

像 OpenAI o1 和 DeepSeek-R1 這樣的推理模型有過度思考的問題。如果你問它們一個簡單的問題,例如“1 + 1 等於多少?”,它們會思考幾秒鐘才能回答。

理想情況下,人工智慧模型應該像人類一樣,能夠確定何時提供直接答案以及何時在回應之前分配額外的時間和資源來思考。 新技術 由研究者提出 元人工智能 و伊利諾大學芝加哥分校 透過訓練模型根據查詢難度分配推理預算,可以實現更快的回應、更低的成本和更好的計算資源分配。
昂貴的推理
大型語言模型 (LLM) 可以透過產生更長的推理鏈(通常稱為「思維鏈」 (CoT))來提升其在推理任務中的表現。 CoT 技術的成功催生了一整套推理時間擴展技術,這些技術迫使模型更深入地「思考」問題,產生並審查多個答案,最終選出最佳答案。
多數投票 (MV) 是推理模型中的關鍵方法,該方法會產生多個答案,並選擇最常被問到的答案。這種方法的問題在於,模型採取統一的行為,將每個輸入視為一個具有挑戰性的推理問題,並消耗不必要的資源來產生多個答案。
智能推理
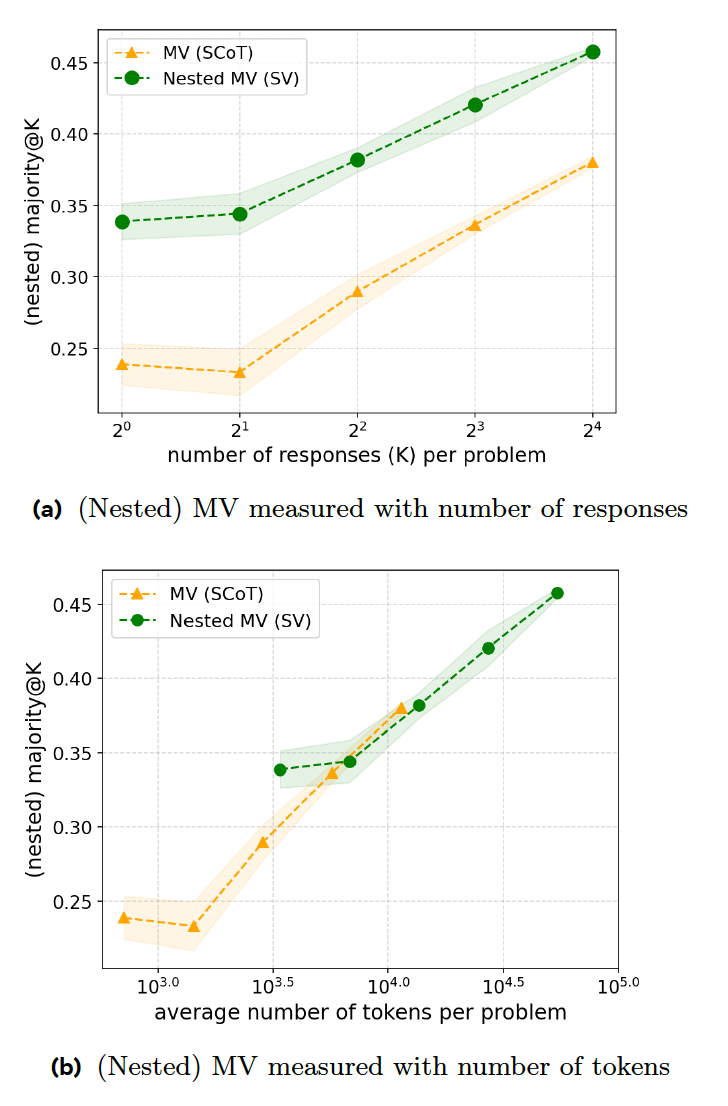
這篇新研究論文提出了一系列訓練技術,旨在提高推理模型的反應效率。第一步是「順序投票」(SV),也就是某個特定答案出現一定次數後,模型就會終止推理過程。例如,要求模型產生最多八個答案,並選擇出現至少三次的答案。如果模型被賦予上述簡單查詢,前三個答案很可能相似,從而提前終止推理,節省時間和計算資源。
他們的實驗表明,在產生相同數量的答案時,SV 在數學競賽題上的表現優於經典的 MV。然而,SV 需要額外的指令和程式碼生成,因此在程式碼與準確率的比率方面與 MV 相當。
第二種技術是自適應順序投票 (ASV),它透過要求模型檢查問題並僅在問題困難時產生多個答案來改進 SV。對於簡單問題(例如 1+1 索賠),模型只需產生一個答案,而無需經過投票過程。這使得模型在處理簡單和複雜問題時都更有效率。
強化學習
雖然 SV 和 ASV 技術都能提高模型效率,但它們需要大量手動標記的資料。為了緩解這個問題,研究人員提出了推理預算約束策略最佳化 (IBPO),這是一種強化學習演算法,可以教導模型根據查詢難度調整推理路徑的長度。
IBPO 旨在允許大型語言模型 (LLM) 在推理預算限制下改進其回應。強化學習演算法透過持續產生 ASV 軌跡、評估反應並選擇能夠提供正確答案和最佳推理預算的結果,使模型能夠超越基於手動標記資料進行訓練所獲得的收益。
他們的實驗表明,IBPO 改善了帕累托前沿,這意味著對於固定的推理預算,在 IBPO 上訓練的模型優於其他基線。
這項發現出自研究人員的警告,目前的人工智慧模型正面臨困境。各公司正在努力尋找高品質的訓練數據,並探索改進模型的其他方法。
一個有前途的解決方案是強化學習,其中模型被賦予一個目標並允許它自己找到解決方案,而不是監督微調(SFT),其中模型在手工標記的例子上進行訓練。
令人驚訝的是,該模型經常能找到人類未曾考慮過的解決方案。這項公式似乎在挑戰美國人工智慧實驗室主導地位的 DeepSeek-R1 中發揮了作用。
研究人員指出,“基於提示的方法和SFT在絕對優化和效率方面存在困難,這支持了SFT本身無法實現自我修正能力的猜想。同時開展的研究也支持了這一觀察結果,表明這種自我修正行為是在強化學習過程中自發產生的,而不是由提示或SFT手動生成的。”
評論被關閉。