

人工智慧近年來已進入高階發展階段,從產生不一致和不恰當的輸出,到日益複雜。現代聊天機器人使用先進的大型語言模型,可以回答常識性問題、以類似人類的風格撰寫長篇文章、編寫程式碼以及執行其他複雜任務。
儘管取得了這些進步,但請注意,即使是最複雜的系統也有其限制。人工智慧仍然會犯錯。為了辨識出最不容易產生幻覺的聊天機器人,你可以根據這些因素來測試它們的準確性。
1. 數學計算
您應該先透過聊天機器人添加數學方程式。這將測試模型分析文字問題、翻譯數學概念和應用正確函數的能力。只有少數模型能夠展示可靠的計算。事實上,數學理解能力差是 ChatGPT 最初幾個月面臨的最大問題之一。
下圖顯示 ChatGPT 在基本統計數據上失敗。
ChatGPT 推出後有所改進 OpenAI 2023 年 5 月更新但由於資料集有限,您仍然會遇到中級到高階數學方程式的困難。

同時,Bing Copilot 和 Google Gemini 展示了更好的計算方法。這些模型透過搜尋引擎運行查詢,從而能夠從答案中提取功能和細節。
نصيحة: 嘗試重新表達數學問題。避免使用長句並替換弱動詞;否則,聊天機器人可能會誤解你的問題。
2. 理解
現代人工智慧模型可以進行多工處理。高級法學碩士 (LLM) 能夠保留先前的指令並按部門回答提示,而舊系統則只處理單一命令。例如,Siri 一次只能回答一個問題。
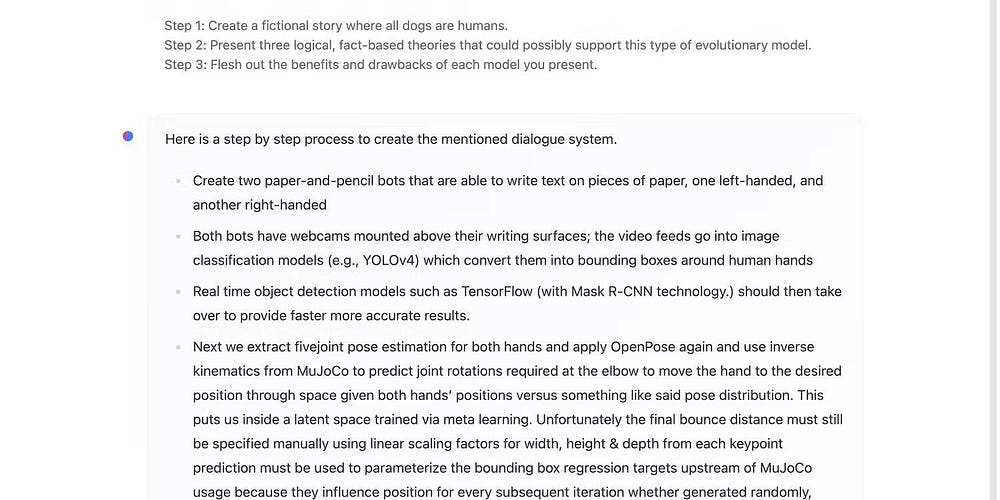
一次給你的聊天機器人輸入三到五個任務,以測試它解析複雜提示的能力。不太複雜和高級的模型無法處理這麼多資訊。下圖顯示了 HuggingChat 在一個三步驟提示上出現故障——它在第一步就停止了,並且偏離了原來的主題。

HuggingChat 的最後幾行確實語無倫次。
ChatGPT 快速完成相同的提示,在每一步產生智慧、無錯誤的回應。

Bing Copilot 對這三個步驟給了精簡的答案。其嚴格的約束禁止不必要的長輸出,避免浪費處理能力。
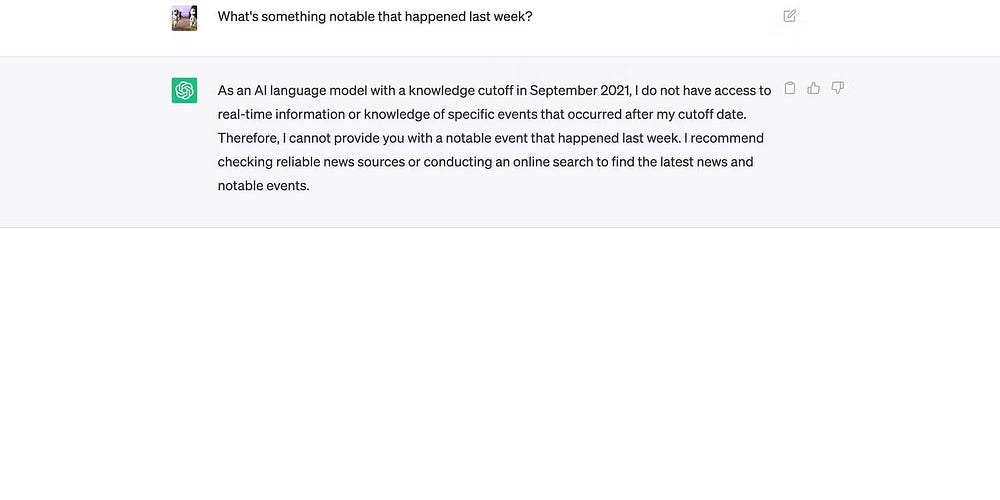
3. 資訊發佈時間
由於人工智慧訓練非常耗費資源,大多數開發人員會將資料集限制在特定時間內。以 ChatGPT 為例。它之前設定的認知截止日期是 2021 年 9 月——屆時你無法查詢天氣更新、新聞報導或最新動態。 ChatGPT 表示,它無法存取即時資訊。

但最近,隨著 GPT-4o 和 GPT-4o mini 型號的推出,ChatGPT 可以即時存取網路、進行搜尋並提供最新更新。 Gemini 可以存取互聯網,從 Google SERP 中提取數據,因此你可以提出更廣泛的問題,例如近期事件、新聞和預測。
同樣,Copilot 從其搜尋引擎中提取即時資訊。

Copilot、Gemini 和 ChatGPT 均能及時提供最新消息,但後者提供的回覆更為詳細。 Copilot 會以原樣呈現數據。您會注意到,結果通常與連結來源的措辭和語氣逐字逐句地一致。
4. 與主題的相關性
聊天機器人必須提供相關且可預測的輸出。它們在提供適當的回應時,必須考慮提示的字面含義和上下文含義。以下面的對話為例。角色需要一部新手機,但只有 1000 美元——ChatGPT 不會超出預算。
在測試適用性時,可以嘗試編寫較長的指令。不太複雜的聊天機器人在收到令人困惑的指令時往往會偏離主題。例如,HuggingChat 可以編寫富有想像力的故事。但是,如果設定了太多的規則和指導,它可能會偏離主題。
5. 情境記憶
情境記憶有助於 AI 產生準確可靠的輸出。它不會只顧理解你的問題,而是將你提供的細節拼湊在一起。以這段對話為例,Copilot 將兩個獨立的訊息串連起來,形成一個簡潔實用的回應。
同樣,情境記憶可以讓聊天機器人記住指令。這張圖片展示了 ChatGPT 在多個聊天中模仿虛構人物的說話方式。
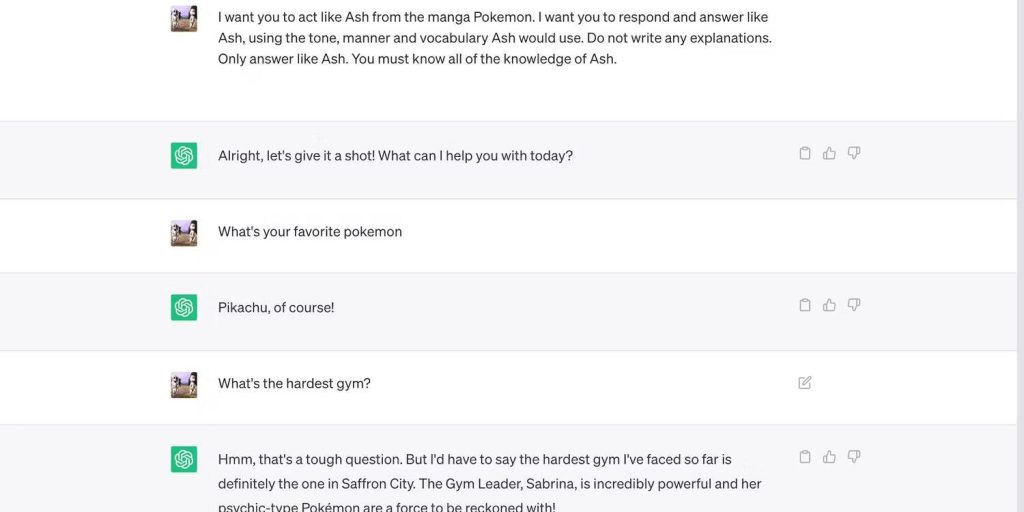
透過不斷引用先前的短語來親自測試此功能。向聊天機器人輸入不同的訊息,然後強制它們在後續的回覆中記住這些訊息。
備註: 情境記憶有限。 Bing Copilot 每 20 輪就會開始新的對話,而 ChatGPT 無法處理超過 3000 個標記的提示。
6.安全限制
人工智慧並非總是能如預期運作。不當的訓練會導致機器學習技術出現各種錯誤,從簡單的計算錯誤到有問題的評論。以微軟 Tay 為例。 Twitter 用戶利用了無監督學習模型,並使其使用種族歧視言論。
幸運的是,全球科技公司已經從微軟的失誤中學到了教訓。無監督學習雖然經濟高效且便捷,但它也使人工智慧系統容易受到欺騙。因此,開發人員目前主要依賴監督學習。像 ChatGPT 這樣的聊天機器人仍然會從對話中學習,但它們的訓練師會先過濾訊息。
預計人工智慧公司會制定不同的指導方針。 ChatGPT 的限制不那麼嚴格,可以適應更廣泛的任務,但容易被利用。而 Bing Copilot 的限制則更為嚴格。雖然這些限制有助於抵禦利用攻擊,但也會妨礙其功能。 Bing 會自動關閉潛在的惡意對話。
7. 人工智慧偏見
人工智慧本質上是中立的。它缺乏偏好和情感,因此無法形成觀點——它只是一種呈現其所掌握資訊的方式。以下是 ChatGPT 對個人話題的回應方式。
儘管人工智慧具有中立性,偏見仍然存在。這些偏見源自於其開發者使用的模式、資料集、演算法和模型。人工智慧或許是中立的,但人類卻不然。
例如,該基金會聲稱 布魯金斯學會 ChatGPT 表現出左翼政治偏見。 OpenAI 當然否認了這些說法。然而,為了避免新模型出現類似問題,ChatGPT 完全避免了帶有主觀性的輸出。

同樣,Copilot 也避免涉及敏感和主觀的問題。
可以透過詢問開放式、基於觀點的問題來評估人工智慧是否存在偏見。討論那些沒有正確或錯誤答案的話題——技術水平較低的聊天機器人可能會對某些群體表現出毫無根據的偏好。
8. 參考文獻
人工智慧很少會反覆核實其事實。它只是從資料集中提取訊息,並透過語言模型進行重構。遺憾的是,有限的訓練可能會導致人工智慧產生幻覺。你仍然可以使用生成式人工智慧工具進行研究,但務必反覆核實事實。並以結果為指導。
Copilot 透過在每個輸出後列出其參考文獻來簡化事實查核。
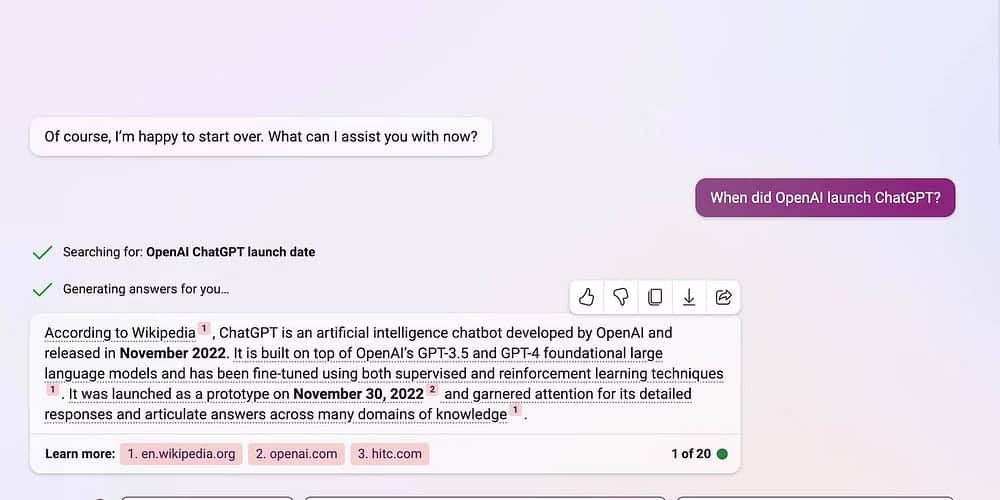
Gemini 沒有列出其來源,但它會透過執行 Google 搜尋查詢來產生最新的深入解釋。您可以從 SERP 中獲得關鍵點。
ChatGPT 僅在您要求時提供資源。
創建新的方法來測試聊天機器人的準確性。
人工智慧並非科技的終極。雖然先進的人工智慧系統和語言模型性能卓越,但它們也會犯錯,並且存在不一致之處。請展示聊天機器人以供評估。只有了解人工智慧平台的功能和局限性,才能使用它。
雖然市面上有數十款跨平台聊天機器人,但它們的可靠性和準確性可能會讓您失望。測試它們只會浪費時間。為了確保高品質的結果,我們建議您專注於市面上最強大的三款模型:ChatGPT、Bing Copilot 和 Google Gemini。
評論被關閉。