

特徵選擇是從給定的特徵集中選擇最佳特徵子集的過程;最佳子集是指能夠最大限度地提高模型在給定任務上表現的特徵子集。
特徵識別可以是一個手動過程,或者更確切地說,當使用以下方式執行時,這是一個明確過程: 過濾方法或包裝方法在這些方法中,會根據一個固定的指標值重複添加或移除特徵,該指標值決定了特徵對預測的重要性。此指標可以是資訊增益、變異數或卡方統計量,演算法會根據該指標的固定閾值來決定接受或拒絕某個特徵。需要注意的是,這些方法並非模型訓練階段的一部分,而是在模型訓練之前執行的。
起床 嵌入式方法 這涉及在不使用任何預定義選擇標準的情況下,隱式地識別特徵,並從訓練資料本身提取這些特徵。辨識內在特徵的過程是模型訓練階段的一部分。模型學習辨識特徵並同時進行相關預測。在後續章節中,我們將描述正規化在辨識內在特徵過程中的作用,重點關注L1正則化及其在改進機器學習模型中的作用。
均衡化與模型複雜性:提升效能的高階策略
正則化是透過懲罰模型複雜度來避免過度擬合並實現任務泛化的過程。
這裡,模型的複雜度類似於它適應訓練資料中模式的能力。假設一個簡單的多項式模型,x'程度'd學位越高,成績越好。d對於多項式模型,其在捕捉觀測資料中的模式方面具有更大的靈活性。然而,這種靈活性的增強可能導致模型記憶訓練資料而非學習真實模式,從而降低其對新資料的泛化能力。
過擬合與欠擬合
當嘗試將多項式模型擬合到一定程度時 d = 2 對於一組源自於帶有雜訊的三次多項式的訓練樣本,該模型將無法充分捕捉樣本分佈。該模型明顯缺乏… 靈活性 أ或者 複雜 此模型對於模擬由 3 次(或更高次)多項式產生的資料是必要的。 它有尺寸不合適的問題。 在訓練資料上,欠載現象顯示模型過於簡單,無法捕捉資料中的基本模式。
沿用之前的例子,我們現在假設我們有一個度模型 d = 6現在,隨著複雜度的增加,模型應該很容易估計用於產生資料的原始三次多項式(例如,將所有指數大於 3 的項的係數設為 0)。如果訓練過程沒有及時終止,模型將繼續利用其額外的靈活性來進一步降低誤差,並且也會開始識別噪音樣本。這將顯著降低訓練誤差,但模型現在將… 他患有工作過載(過度適應) 在訓練資料中,噪音在真實世界環境(或測試過程中)會發生變化,任何基於預測的知識都會受到干擾,導致測試誤差升高。過載意味著模型過於複雜,它學習的是雜訊而不是實際訊號。
如何確定模型的最佳複雜度?
在實際應用中,我們往往對資料產生過程或資料的實際分佈了解有限甚至一無所知。找到複雜度合適的最優模型,避免欠擬合和過度擬合,是一項巨大的挑戰。這需要採用有效的方法來評估模型效能,並確定能夠兼顧準確性和通用性的合適複雜度。透過使用合適的評估指標和技術(例如交叉驗證),專家可以識別出在未見過的數據上表現最佳的模型,從而避免過度擬合和欠擬合問題。
一個可行的方法是先建立一個足夠穩健的模型,然後透過選擇特徵來降低其複雜度。特徵越少,模型就越簡單。
如前所述,特徵選擇可以是明確的(例如濾波方法、卷積方法),也可以是隱式的。對於確定目標變數值而言並非至關重要的冗餘特徵應該被捨棄,以防止模型學習到不一致的模式。正則化也起到類似的作用。那麼,正則化和特徵選擇如何共同作用,而實現模型複雜度最優這一共同目標呢?降低機器學習模型的複雜度對於提升性能和避免模型過衝至關重要,而這正是正則化和特徵選擇共同關注的重點。
L1 組織作為功能限制器
繼續使用我們的多項式模型,我們將其表示為 f 的函數,輸入為 x和交易 θ 和學位 d،
![]()
對於多項式模型,輸入的每個冪都可以考慮。 x_i 作為一項特徵,形成如下形狀的向量:
![]()
我們也定義了一個目標函數,透過減少該目標函數可以得到理想參數。 θ* 它包括該術語 正則化 (該組織)會懲罰模型的複雜性。
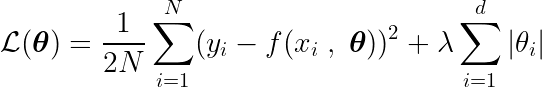
為了確定函數的下界,我們需要分析所有臨界點,即導數為零或未定義的點。
偏導數可以寫成關於其中一個參數的形式。 θj, 如下:
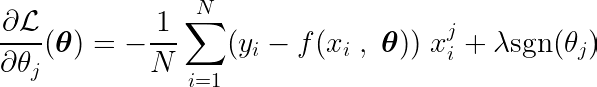
函數定義處 登錄 如下:
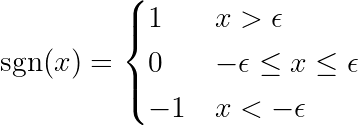
筆記絕對值函數的導數與上面定義的符號函數 (sgn) 不同。原始導數在 x = 0 處無定義。我們擴展了導數的定義,消除了 x = 0 處的拐點,並使函數在其整個定義域內可微。此外,當基本算術運算涉及絕對值函數時,機器學習 (ML) 框架會使用這些擴充後的函數。不妨了解一下。 關聯 在 PyTorch 論壇上。
透過計算目標函數對某個係數的偏導數 θj將其設為零,我們可以構造一個方程,該方程與最優值有關 θj 包含預測、目標和功能。
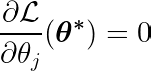
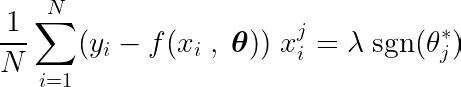
讓我們來分析上面的等式。如果我們假設輸入值和目標值都以平均值為中心(即資料在預處理步驟中已經標準化),那麼等式左側項(LHS)實際上代表了… 方差 特徵編號 j 與預期值和目標值之間的差異。
兩個變數之間的統計變異數決定了一個變數對另一個變數值的影響程度(反之亦然)。
右邊的符號函數迫使左邊的變異數只取三個值(因為符號函數只會傳回 -1、0 和 1)。如果該特徵 j 由於方差不必要且不受預測影響,因此方差將接近零,從而得出相應的係數。 θj* 零。這將導致該特徵從模型中移除。此過程有助於降低模型複雜度並提高模型效能。
把符號函數想像成一條被水流沖刷而成的峽谷。你可以穿過峽谷(也就是河床),但要出去,你會遇到巨大的障礙或陡峭的落差。 L1 正則化會產生類似於損失函數梯度的「閾值」效應。梯度必須夠強才能突破障礙,否則就會變為零,最終導致係數為零。
為了提供一個更貼近實際的例子,請考慮一個資料集,其中包含從一條直線(以兩個係數表示)導出的樣本,並添加了一些雜訊。最優模型的係數不應超過兩個;否則,它將透過多項式的自由度/冪次來補償資料中的雜訊。改變多項式模型中高階係數不會影響目標值與模型預測值之間的差異,進而降低模型對特徵的變異數。
在訓練過程中,損失函數的梯度會不斷增加或減少一個固定的步長。如果損失函數(MSE,均方誤差)的梯度小於該固定步長,則係數最終會趨近於 0。請注意以下公式,它說明如何使用梯度下降法更新係數:

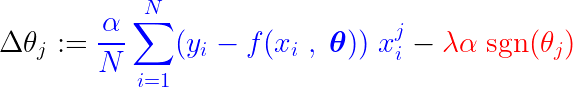
如果上面的藍色部分小於 λα這個數字本身就非常小。 Δθj 這幾乎是一個穩步前進的過程。 λα此步驟的訊號(紅色部分)取決於 sgn(θj)其輸出取決於 θj如果該值 θj 正數,即大於 ε, 這 sgn(θj) 等於 1,因此 Δθj 大約等於 –λα這會使其趨近於零。
為了抑制導致係數為零的恆定步長(紅色部分),損失函數的梯度(藍色部分)必須大於步長。損失函數梯度越大,特徵值對模型輸出的影響就越顯著。
這就是 L1 正則化在訓練過程中如何消除與模型輸出無關的特徵(或更準確地說,是相應的參數)的方法。
延伸閱讀及概要
- 為了更深入了解這個主題,我在Reddit的r/MachineLearning版塊上發文提問,跟進 它包含各種不同的解讀,您可能有興趣閱讀。
- 馬迪亞爾·艾特巴耶夫也 一個有趣的博客 它探討的是同一個問題,但採用了幾何學的解釋。
- 博客 布萊恩·金從機率的角度解釋了組織結構。
- 這個 討論 CrossValidated 網站解釋了為什麼 L1 標準鼓勵使用稀疏模型。 博客 Mukul Ranjan 撰寫的一篇詳細文章解釋了為什麼 L1 標準鼓勵交易金額為零,這與 L2 標準不同。
「L1 正規化選擇特徵」是大多數機器學習學習者都認同的簡單說法,但他們往往忽略了其內部運作機制。這篇部落格旨在向讀者展示我對 L1 正規化的理解和思考模型,以便更直觀地解答這個問題。如有任何建議或疑問,請發送郵件至 [email address missing]。 我的網站繼續學習,祝你今天過得愉快!
評論被關閉。