

蘋果的人工智慧努力尚未取得與Google Gemini、微軟 Copilot 或 OpenAI ChatGPT 同等的成效,這給該公司在這一領域帶來了挑戰。該公司的人工智慧工具包名為 蘋果情報它不僅沒有為用戶改變iPhone和Mac的功能,而且還導致了公司內部的管理危機,迫使其重新評估該領域的策略。
看來用戶數據或許能扭轉乾坤。今天,該公司發表了一篇關於機器學習的研究論文。 紙 它詳細介紹了一種利用儲存在iPhone上的資料訓練內建AI的新方法,首先從電子郵件開始。這些資訊將用於改善電子郵件摘要和寫作工具等功能,從而增強使用者體驗並提高這些工具的效率。
AI訓練簡述
在深入探討細節之前,我們先簡單概括一下人工智慧工具的工作原理。第一步是訓練,本質上就是給「人工智慧大腦」輸入大量人工產生的資料。例如書籍、文章、研究論文等等。輸入的資料越多,它的反應就越好。
這是因為聊天機器人(技術上稱為大型語言模型 (LLM))試圖理解單字之間的模式和關係。像 ChatGPT 這樣的工具(現在已整合到 Siri 和 Apple Intelligence 中)本質上就是詞彙預測工具。
但目前可用於人工智慧訓練的資料量有限,而且整個過程極為耗時且成本高昂。那麼,為什麼不使用人工智慧產生的資料來訓練自己的人工智慧呢?研究表明,這樣做實際上會「毒害」人工智慧模型。這意味著不準確的回應、無意義的指令和誤導性的輸出。
蘋果計劃如何修復其人工智慧?

AI工具的反應能力並非僅僅依賴合成數據,而是可以透過不斷微調來提升。然而,訓練AI助理的最佳方法是為其提供更多現實世界的人類資料。儲存在你手機上的資料是這類資訊最豐富的來源,但公司根本無法做到這一點。
這將是對隱私的嚴重侵犯,並引發訴訟。
蘋果的意圖是間接查看你的電子郵件,而無需複製或將其發送到其伺服器。簡而言之,你的所有資料都保留在你的手機上。此外,蘋果實際上不會「閱讀」你的電子郵件。相反,它只是將它們與一組合成電子郵件進行比較。
這裡的關鍵在於確定哪些合成資料最接近人工撰寫的電子郵件。這將使蘋果了解人類在對話中與之互動的最真實的數據類型。據報道,到目前為止,蘋果「通常」使用合成資料來訓練其人工智慧。 彭博社.
該公司解釋說:「這些合成數據可以用來在更具代表性的數據上測試我們模型的質量,並找出摘要等功能方面需要改進的地方。」這可能會在未來顯著改善 Siri 和 Apple Intelligence 的響應效果。
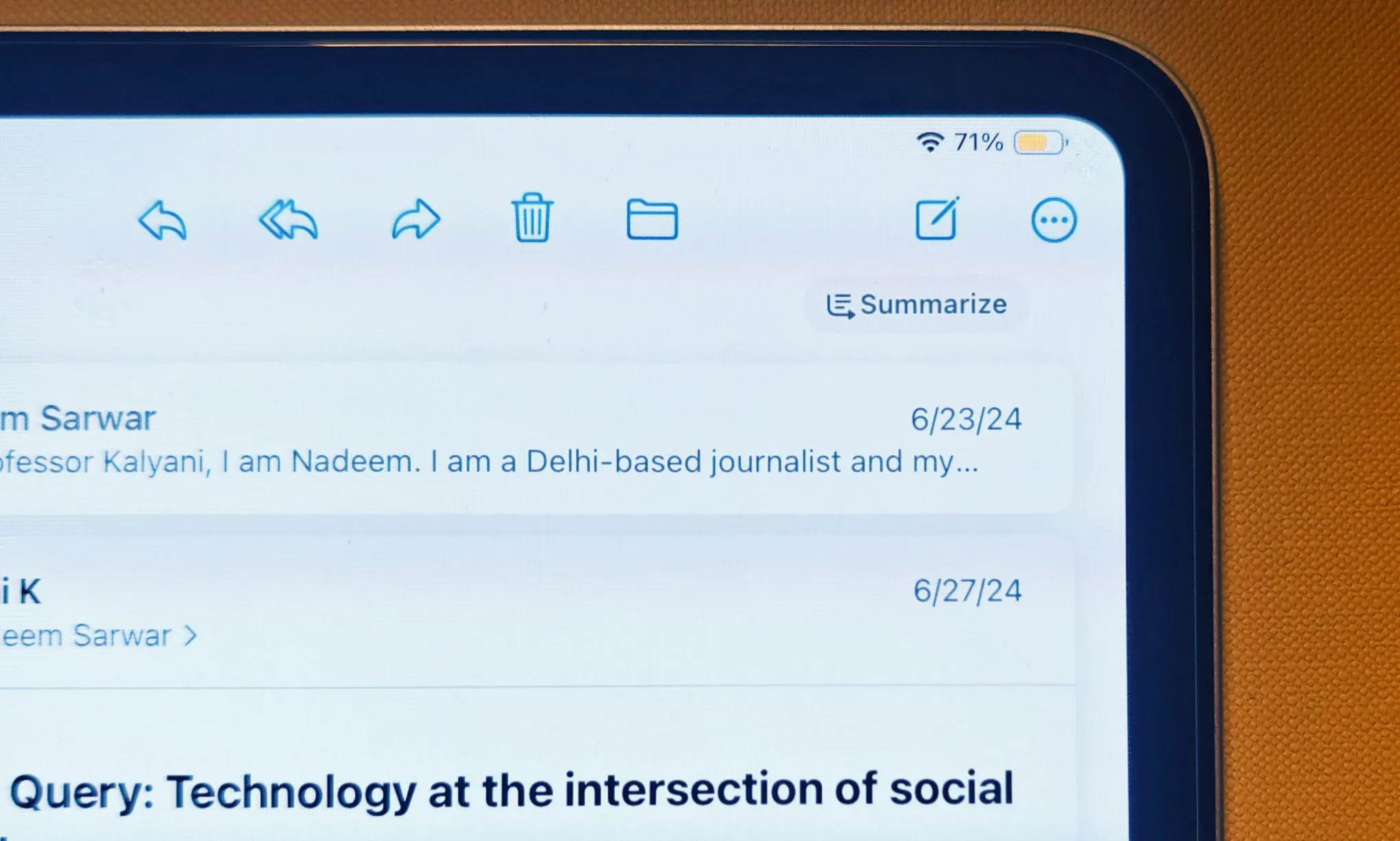
基於對現實世界人類數據的學習,蘋果旨在改進其電子郵件摘要係統及其寫作工具包的某些元素。該公司強調,「樣本電子郵件的內容永遠不會離開設備,也不會與蘋果共享。」蘋果表示,他們已經為 Genmoji 部署了類似的以隱私為重點的訓練系統。
為什麼這是向前邁出的關鍵一步?
目前,郵件應用程式中 Apple Intelligence 提供的摘要資訊往往非常混亂,有時甚至完全無法理解。應用通知目前的情況也一樣,而且情況已經非常糟糕,以至於蘋果在收到 BBC 因其歪曲新聞報道而提出的批評後,被迫暫時停用了這些通知。
情況非常糟糕,以至於摘要通知在我們團隊聊天中變成了一個笑話。在嘗試總結對話或電子郵件時,Apple Intelligence 經常將一些毫無意義或與實際情況完全不同的句子拼湊在一起。這會對使用者體驗產生負面影響,並降低智慧助理的效率。
根本問題在於,人工智慧仍然難以理解語境和人類意圖。解決這個問題的最佳方法是使用更具情境感知能力的材料進行訓練,並賦予其適當的語境理解能力。近年來,一些具備推理能力的人工智慧模式應運而生,但它們並非萬靈丹。這些新模型有望顯著提升理解準確性,但仍需要高品質的訓練資料。

蘋果描述的方法聽起來像是兩全其美。該公司表示:「這個過程使我們能夠改進合成電子郵件的主題和語言,這有助於我們訓練模型,使其在電子郵件摘要等功能中產生更好的文字輸出,同時保護隱私。」這種方法將效能提升與用戶資料的保密性結合在一起。
現在,好消息來了。蘋果不會讀取全球 iPhone 和 Mac 上儲存的所有電子郵件。相反,它採取了一種“選擇加入”的方式。只有明確同意與蘋果共享裝置分析資料的使用者才會參與 AI 訓練過程。這確保了使用者對自己的資料擁有完全的控制權。
您可以按照以下路徑啟用它:設定 > 隱私權和安全性 > 分析和改進。據報道,該公司將在即將發布的 iOS 18.5、iPad 18.5 和 macOS 15.5 測試版更新中開始啟動該計劃。針對開發者的類似版本已經發布。這使開發者可以開始測試新功能並提供效能改進的回饋。
評論被關閉。